amazon-science/mm-cot
Teaching LLMs to read the figures, not just the text
MM-CoT forces a language model to write out its visual reasoning before answering, using a two-stage pipeline built for the ScienceQA benchmark.
Not currently ranked — collecting fresh signals.
star history
What it does
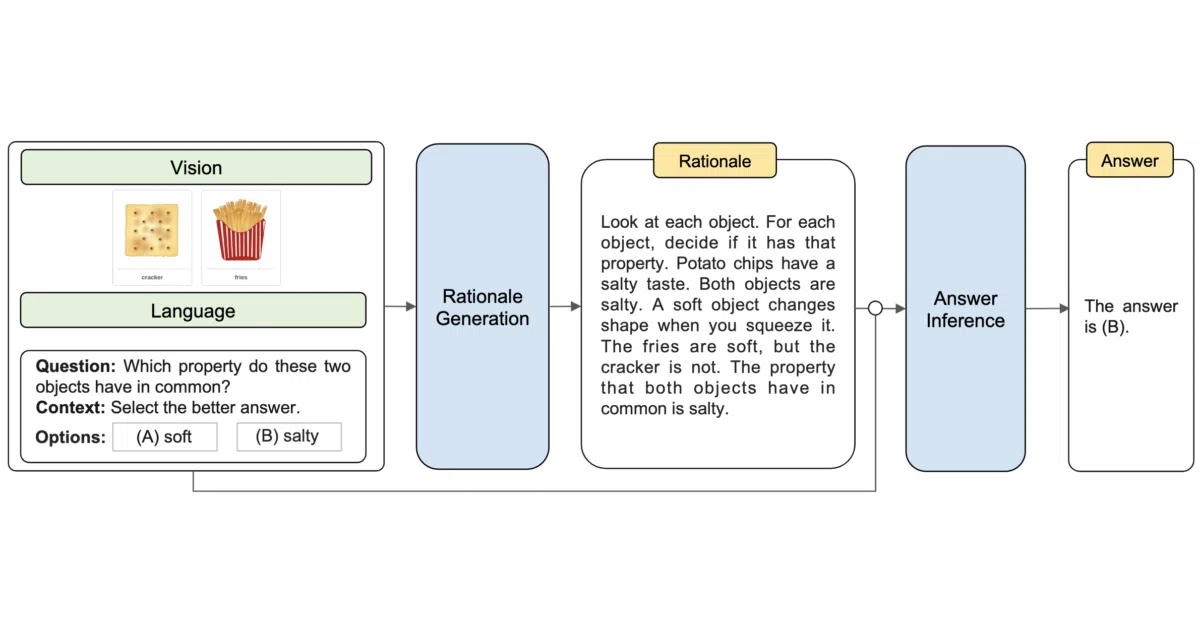
MM-CoT is the official implementation of a paper that injects vision features into chain-of-thought reasoning. It trains a Flan-Alpaca model in two passes: first generating an explanatory rationale from text, images, and captions, then using that rationale to infer a final answer. The entire setup is built around the ScienceQA dataset, with pre-extracted vision features and optional InstructBLIP captions.
The interesting bit
Instead of dumping image embeddings into a single end-to-end prompt, the framework decouples the problem. The model first writes a chain-of-thought conditioned on the visual input, then feeds that rationale into a second stage for answer selection. It is the kind of architectural constraint that tries to prevent the model from ignoring the diagram.
Key highlights
- Two-stage pipeline: rationale generation followed by answer inference, sharing the same underlying architecture but swapping inputs and outputs.
- Consumes pre-extracted vision features (DETR, ResNet, CLIP, ViT) and optional InstructBLIP captions.
- Trained checkpoints and extracted features are hosted on Hugging Face.
- Licensed under Apache 2.0; code is adapted from ScienceQA, Transformers, and timm.
Caveats
- The repository description warns “stay tuned and more will be updated,” suggesting the release is still filling out.
- Everything is tightly coupled to the ScienceQA dataset and
declare-lab/flan-alpaca-large; generalizing to other domains or backbones would require significant surgery. - The README is mostly shell commands and path references, with little discussion of results, ablations, or performance numbers.
Verdict
Worth a look if you are reproducing the ScienceQA paper or studying structured multimodal reasoning pipelines. Skip it if you need a general-purpose vision-language model you can drop in elsewhere.
Frequently asked
- What is amazon-science/mm-cot?
- MM-CoT forces a language model to write out its visual reasoning before answering, using a two-stage pipeline built for the ScienceQA benchmark.
- Is mm-cot open source?
- Yes — amazon-science/mm-cot is open source, released under the Apache-2.0 license.
- What language is mm-cot written in?
- amazon-science/mm-cot is primarily written in Python.
- How popular is mm-cot?
- amazon-science/mm-cot has 4k stars on GitHub.
- Where can I find mm-cot?
- amazon-science/mm-cot is on GitHub at https://github.com/amazon-science/mm-cot.