a-ghorbani/pocketpal-ai
Chat with AI models that never phone home
It gives iOS and Android users a way to download and chat with small language models without sending a single prompt to the cloud.
Velocity · 7d
+13
★ / day
Trend
↘cooling
star history
What it does
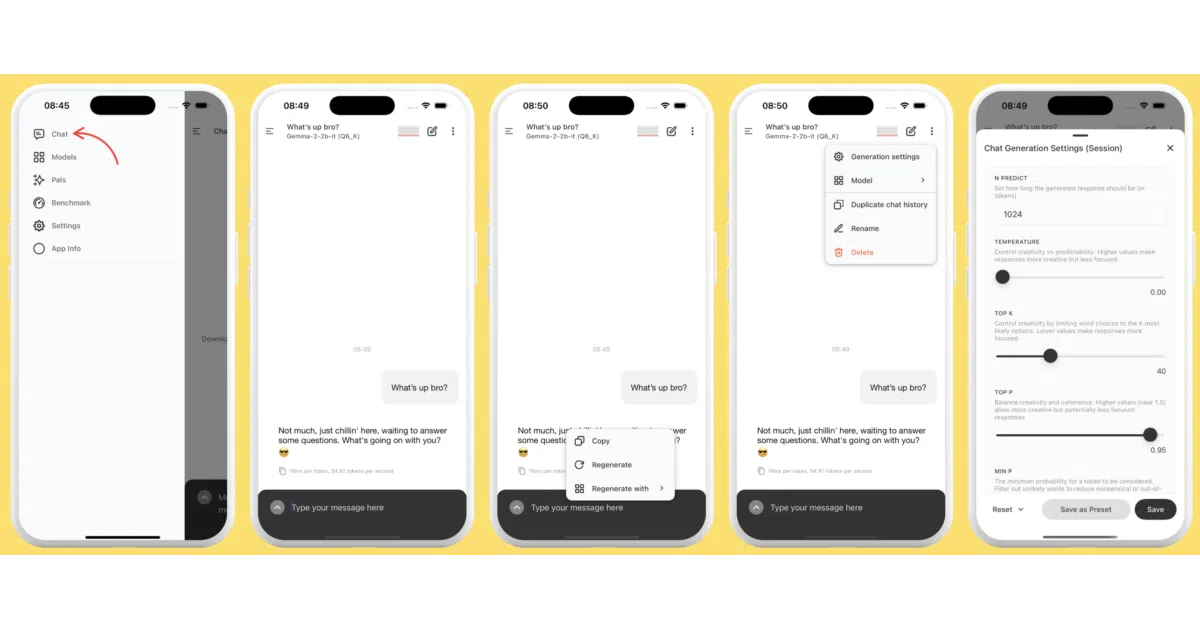
PocketPal AI is a React Native app that downloads and runs quantized small language models directly on iOS and Android devices. It wraps llama.cpp via llama.rn to handle on-device inference, letting users browse a built-in Hugging Face hub to load models like Phi, Gemma 2, Qwen, and Danube. All chat processing happens locally; conversations and prompts never leave the phone unless you explicitly opt in to share benchmark scores or feedback.
The interesting bit
The app treats your phone like a scarce compute resource to be carefully managed. It auto-offloads models when backgrounded to save RAM, keeps the screen awake only during token generation, and exposes raw inference knobs—temperature, BOS tokens, chat templates—that are usually hidden behind cloud APIs. The “Pals” feature even lets you generate system prompts by asking another AI to write them for you.
Key highlights
- Runs fully offline after model download; no network required for inference.
- Browse and download GGUF models directly from the Hugging Face Hub, including gated ones via personal access tokens.
- Built-in benchmarking tool that logs tokens-per-second and memory usage, with an optional public leaderboard.
- “Pals” system for creating multiple persistent personas (assistant or roleplay) with distinct system prompts and settings.
- Supports phones and tablets, including iPad landscape mode, with localization for Japanese and Chinese.
Caveats
- Copying text from the chat currently strips some formatting; the README notes this is a known limitation.
Verdict
Ideal for privacy-conscious mobile users who want to experiment with small models without a data connection. Skip it if you need large frontier models or heavy context windows—your phone’s RAM is still the hard ceiling.
Frequently asked
- What is a-ghorbani/pocketpal-ai?
- It gives iOS and Android users a way to download and chat with small language models without sending a single prompt to the cloud.
- Is pocketpal-ai open source?
- Yes — a-ghorbani/pocketpal-ai is open source, released under the MIT license.
- What language is pocketpal-ai written in?
- a-ghorbani/pocketpal-ai is primarily written in TypeScript.
- How popular is pocketpal-ai?
- a-ghorbani/pocketpal-ai has 7.6k stars on GitHub and is currently cooling off.
- Where can I find pocketpal-ai?
- a-ghorbani/pocketpal-ai is on GitHub at https://github.com/a-ghorbani/pocketpal-ai.