WongKinYiu/yolov9
YOLOv9: programmable gradients for object detection
A research implementation that tries to make neural networks learn what you actually want them to learn, instead of what the data happens to teach.
Not currently ranked — collecting fresh signals.
star history
What it does
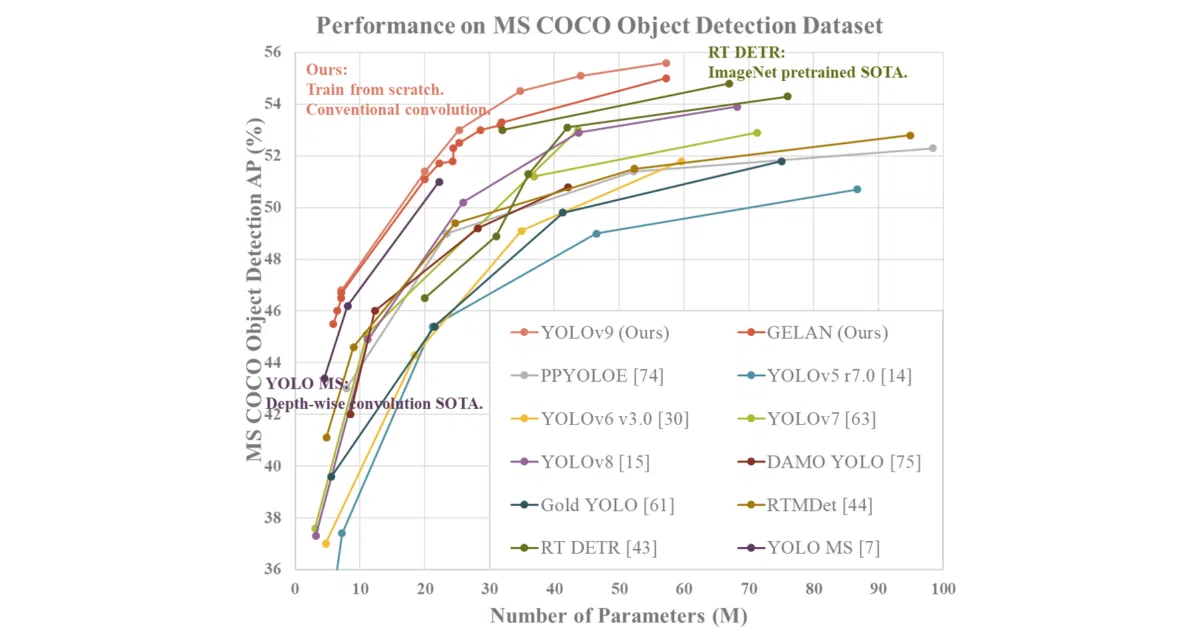
This is the official PyTorch implementation of the YOLOv9 paper, which adds “Programmable Gradient Information” to the standard YOLO object-detection pipeline. It trains and runs inference on the MS COCO dataset, supports single- and multi-GPU setups, and ships with five model sizes from Tiny (2.0M parameters) to Extra (57.3M parameters).
The interesting bit
The core claim is PGI — a mechanism to control what gradient information flows through the network so the model learns task-relevant features rather than spurious correlations. The repo also includes GELAN, a lighter architecture family, and a re-parameterization notebook for compressing trained models.
Key highlights
- Five pretrained checkpoints: YOLOv9-T/S/M/C/E, plus GELAN variants
- MS COCO validation numbers published: YOLOv9-E hits 55.6% AP at 640px
- Docker setup with NVIDIA PyTorch base image; distributed training via
torch.distributed.launch - Export recipes scattered across issues: ONNX, TensorRT, TFLite, OpenVINO, ONNXSlim
- Community integrations tracked in issues: ROS, Julia, MLX, ByteTrack, DeepSORT, Comet, MLflow
Caveats
- README is mostly a performance table and shell snippets; the actual PGI mechanism is not explained in the repo — you need the paper
- “Useful Links” section is a dump of GitHub issue URLs, not organized documentation
- Some model variants and the ReLU ablation are marked “will be released after the paper be accepted”
Verdict
Worth a look if you’re running YOLO in production and want to experiment with gradient-level architectural tweaks. Skip if you need polished tooling or a stable API — this is a research release with community glue code.
Frequently asked
- What is WongKinYiu/yolov9?
- A research implementation that tries to make neural networks learn what you actually want them to learn, instead of what the data happens to teach.
- Is yolov9 open source?
- Yes — WongKinYiu/yolov9 is open source, released under the GPL-3.0 license.
- What language is yolov9 written in?
- WongKinYiu/yolov9 is primarily written in Python.
- How popular is yolov9?
- WongKinYiu/yolov9 has 9.5k stars on GitHub.
- Where can I find yolov9?
- WongKinYiu/yolov9 is on GitHub at https://github.com/WongKinYiu/yolov9.