Walter0807/MotionBERT
A unified motion transformer for pose, action, and body mesh
A single pretrained motion transformer that finetunes into 3D pose estimators, action recognizers, or mesh recovery models.
Not currently ranked — collecting fresh signals.
star history
What it does
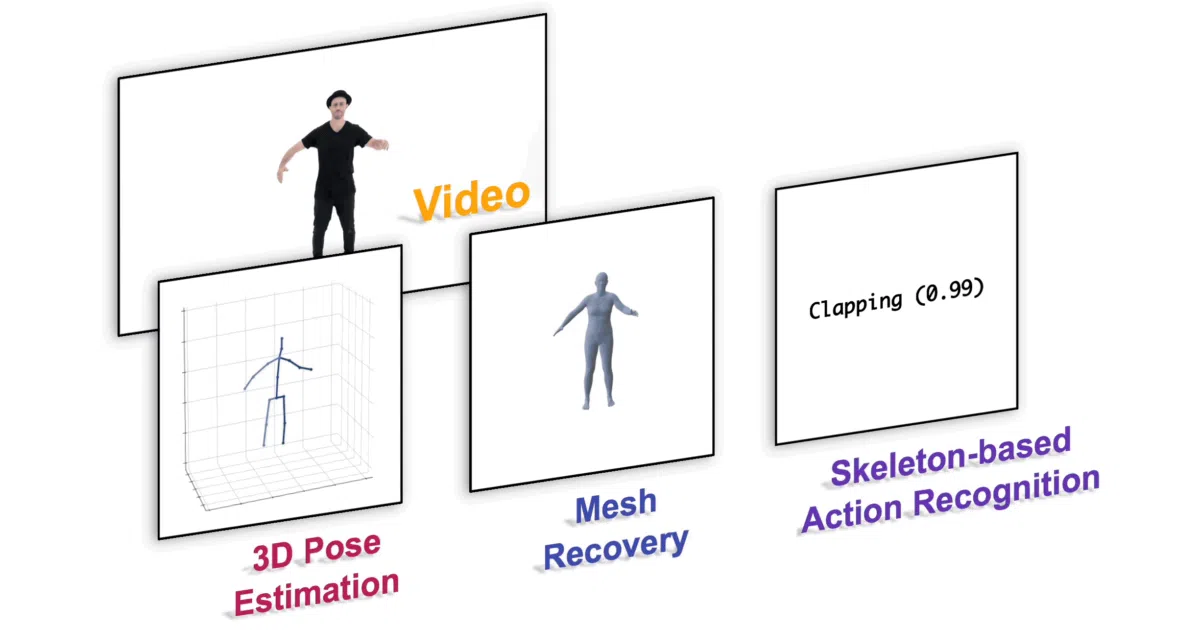
MotionBERT is the official PyTorch release of an ICCV 2023 paper that treats human motion understanding as a unified representation learning problem. It pretrains a spatio-temporal transformer, DSTformer, on 2D skeleton sequences to produce motion embeddings. Those embeddings then finetune into task-specific heads for 3D pose estimation, skeleton-based action recognition, or 3D mesh recovery.
The interesting bit
Instead of training separate specialist networks from scratch, the same pretrained backbone handles diverse downstream tasks. The model ingests 2D keypoint tracks rather than raw pixels, which sidesteps RGB complexity and makes it portable across any video source that can produce skeletons. A lightweight MotionBERT-Lite variant delivers similar finetuned performance with lower computation overhead.
Key highlights
- Single pretrained encoder finetuned for pose, action, and mesh tasks
- Accepts variable-length sequences up to 243 frames of 17 H36M-format keypoints
- Achieves 37.2mm MPJPE on Human3.6M and 97.2% top-1 accuracy on NTU RGB+D action recognition
- Provides both a 162MB full model and a 61MB lite variant
- Supports in-the-wild inference via an RGB-to-2D-pose preprocessing pipeline
Caveats
- RGB videos require a multi-step preprocessing pipeline: extract 2D poses, convert to H36M-format 17 keypoints, then feed to the model; it does not ingest raw pixels end-to-end.
- Input is constrained to 17 body keypoints; other skeleton formats must be converted first.
Verdict
Worth a look if you need a plug-in motion representation for human-centric video analysis and already have—or can easily generate—2D skeleton tracks. Skip it if you need a fully end-to-end RGB-to-3D pipeline without intermediate pose extraction, or if your domain involves non-human motion.
Frequently asked
- What is Walter0807/MotionBERT?
- A single pretrained motion transformer that finetunes into 3D pose estimators, action recognizers, or mesh recovery models.
- Is MotionBERT open source?
- Yes — Walter0807/MotionBERT is open source, released under the Apache-2.0 license.
- What language is MotionBERT written in?
- Walter0807/MotionBERT is primarily written in Python.
- How popular is MotionBERT?
- Walter0807/MotionBERT has 1.4k stars on GitHub.
- Where can I find MotionBERT?
- Walter0807/MotionBERT is on GitHub at https://github.com/Walter0807/MotionBERT.