ViTAE-Transformer/ViTPose
Just Add a Decoder: ViT as a Strong Pose Baseline
It turns out generic MAE-pretrained Vision Transformers can estimate human keypoints without custom pose-specific layers.
Not currently ranked — collecting fresh signals.
star history
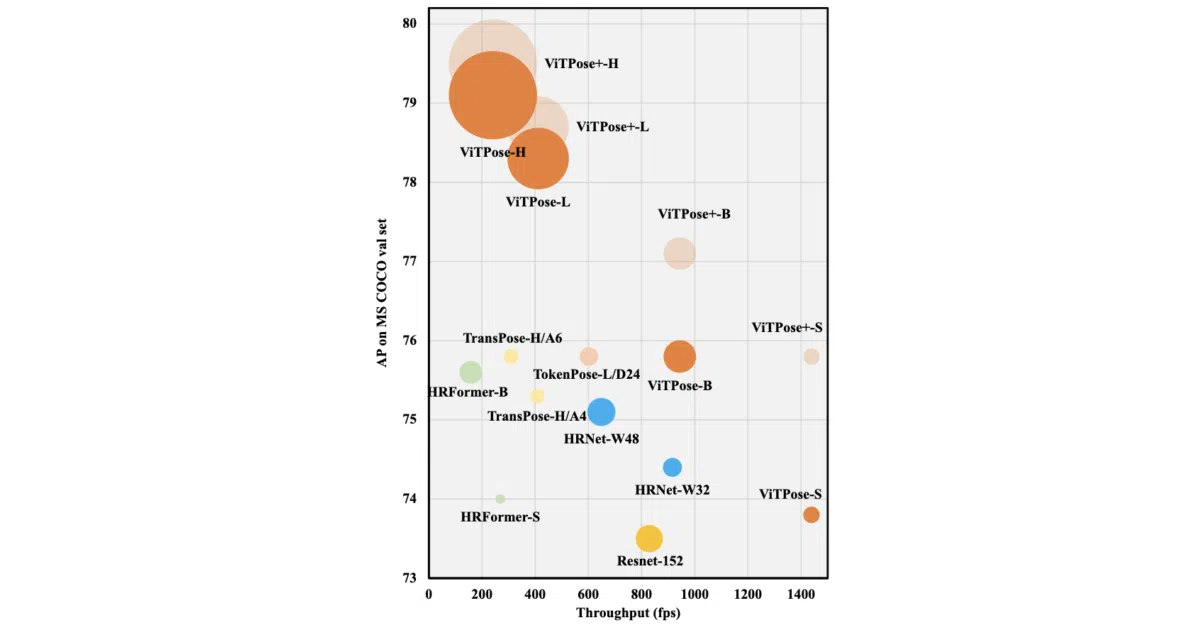
What it does ViTPose treats human pose estimation as a transfer-learning problem for standard Vision Transformers. It takes MAE-pretrained ViT backbones—Small through Huge—and adds a decoder to predict keypoint heatmaps on datasets like MS COCO, AIC, and MPII. ViTPose++ pushes the same architecture into multi-task territory, training a single model on human and animal pose datasets including AP10K, APT36K, and WholeBody.
The interesting bit Instead of inventing a new pose-specific architecture, the authors ask whether an off-the-shelf ViT backbone plus a simple decoder is enough. The answer appears to be yes: the largest variant hits 81.1 AP on COCO test-dev, implying that MAE pretraining carries most of the load.
Key highlights
- Classic and simple decoder variants; the simple decoder loses less than 0.4 AP on COCO val across all sizes
- Model zoo spans Small to Giant, with training configs, logs, and OneDrive weights
- ViTPose++ trains one model jointly on six human and animal pose datasets
- Web demos on Hugging Face Spaces for image and video
- Small-size MAE checkpoint hosted in-repo; larger backbones link to the official MAE repository
Caveats
- CrowdPose training images may duplicate validation images in other datasets, which the authors flag as an evaluation hazard
- Pretrained backbones for Base, Large, and Huge are not stored in this repo; they must be fetched from the separate MAE repository
Verdict A solid starting point for researchers benchmarking pose estimation or stress-testing MAE transfer. Skip it if you are looking for a fully self-contained SDK with all weights in one place.
Frequently asked
- What is ViTAE-Transformer/ViTPose?
- It turns out generic MAE-pretrained Vision Transformers can estimate human keypoints without custom pose-specific layers.
- Is ViTPose open source?
- Yes — ViTAE-Transformer/ViTPose is open source, released under the Apache-2.0 license.
- What language is ViTPose written in?
- ViTAE-Transformer/ViTPose is primarily written in Python.
- How popular is ViTPose?
- ViTAE-Transformer/ViTPose has 2.1k stars on GitHub.
- Where can I find ViTPose?
- ViTAE-Transformer/ViTPose is on GitHub at https://github.com/ViTAE-Transformer/ViTPose.