TimoBolkart/voca
Your voice, now in 3D mesh form
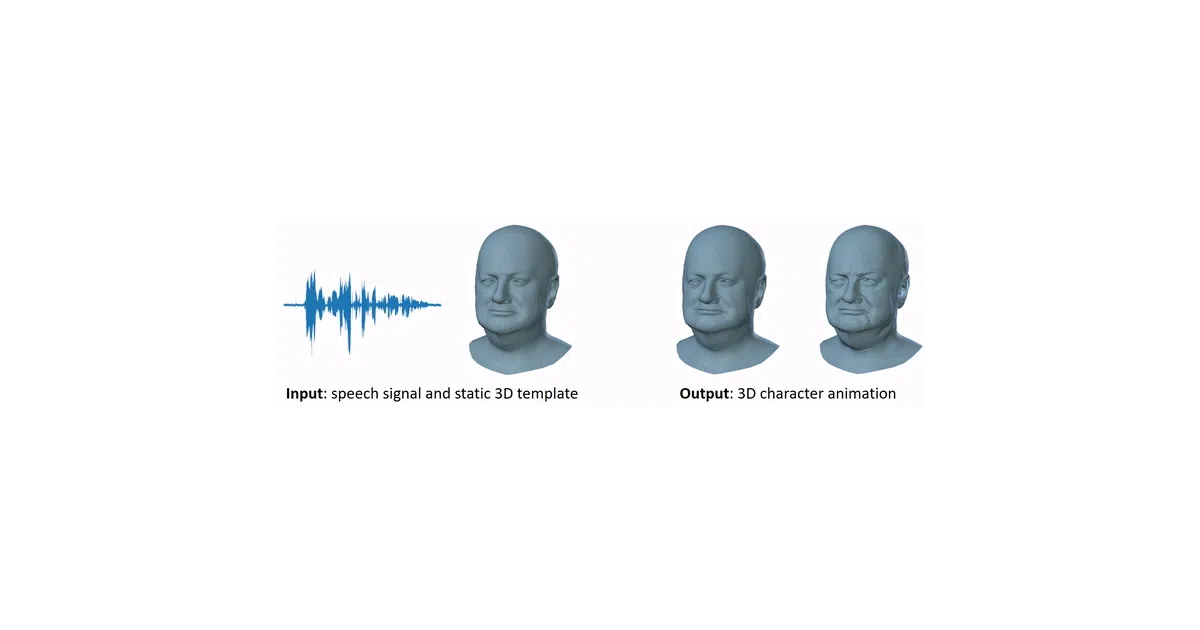
VOCA turns arbitrary speech audio into animated facial geometry for any static character mesh.
Not currently ranked — collecting fresh signals.
star history
What it does VOCA is a speech-driven facial animation framework that takes an audio file and a static 3D character mesh, then outputs a sequence of animated meshes synced to the speech. It is built on the FLAME morphable face model and trained on VOCASET, a 4D scan dataset of 12 speakers. The repository includes inference, training code, and utilities for editing the resulting animations.
The interesting bit The clever part is the decoupling: VOCA learns speaking styles from audio in a speaker-conditional way (via one-hot encoding), yet generalizes to new identities by animating arbitrary FLAME-topology templates. You can even generate a template from a single image using RingNet, then make it talk.
Key highlights
- Trained on ~29 minutes of 4D scans at 60 fps from MPI-IS
- Outputs meshes in FLAME topology, enabling post-hoc edits: eye blinks, identity shape tweaks, head pose changes
- Includes scripts to reconstruct FLAME parameters from output sequences for further manipulation
- Supports textured rendering via pyrender (with a fallback for headless environments)
- TensorFlow 1.14.0 codebase with TensorBoard training visualization
Caveats
- Requires TensorFlow 1.14.0 and Python 3.6.8 — decidedly not current
- The “eye blink” demo explicitly warns it “does not resemble a true eye blink” and only works with FLAME2019
- Non-commercial and scientific research license only; data and pretrained models must be downloaded separately from MPI-IS
Verdict Worth exploring if you need a baseline for speech-driven 3D face animation or want to experiment with FLAME-based pipelines. Skip it if you need production-ready, modern tooling or commercial usage.
Frequently asked
- What is TimoBolkart/voca?
- VOCA turns arbitrary speech audio into animated facial geometry for any static character mesh.
- Is voca open source?
- Yes — TimoBolkart/voca is an open-source project tracked on heatdrop.
- What language is voca written in?
- TimoBolkart/voca is primarily written in Python.
- How popular is voca?
- TimoBolkart/voca has 1.3k stars on GitHub.
- Where can I find voca?
- TimoBolkart/voca is on GitHub at https://github.com/TimoBolkart/voca.