Tencent-Hunyuan/HunyuanVideo
Tencent's 13B-parameter open video model goes toe-to-toe with closed rivals
A research team bet that scale and a repurposed MLLM text encoder could close the gap between open-source and proprietary video generation.
Not currently ranked — collecting fresh signals.
star history
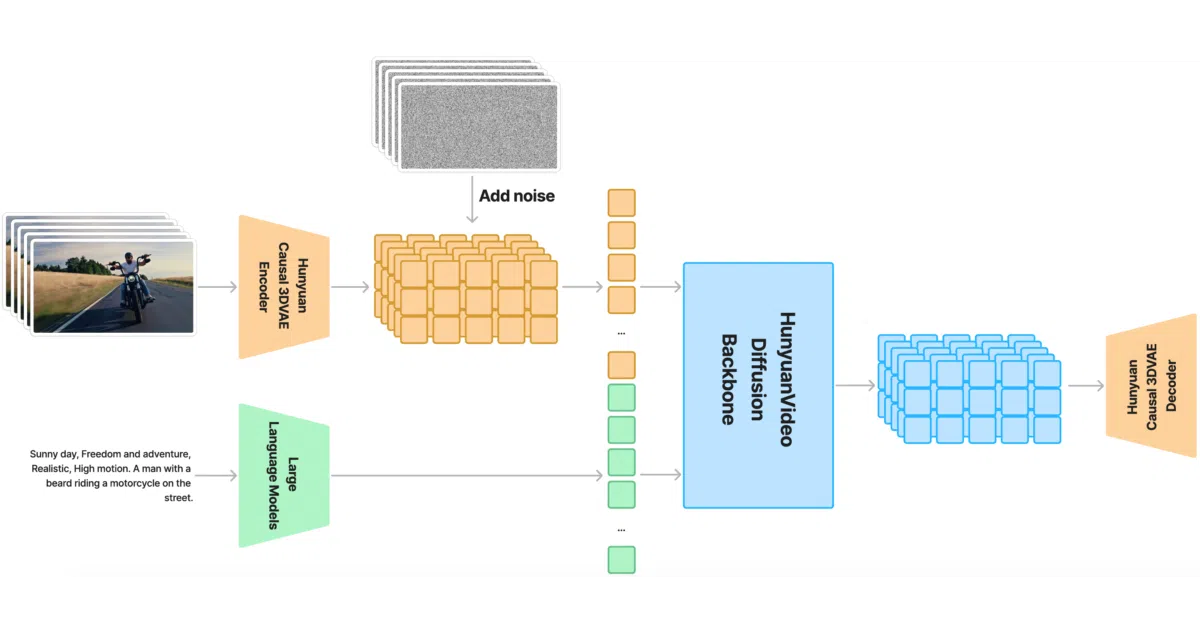
What it does HunyuanVideo is a text-to-video diffusion transformer with over 13 billion parameters—the largest open-source video model at release. It generates 720p video from text prompts using PyTorch inference code and officially released weights. The repo includes single-GPU scripts, multi-GPU parallel inference via xDiT, FP8 quantized weights for memory relief, and a Gradio web demo.
The interesting bit Instead of the usual CLIP-plus-T5 text encoder combo, the team uses a decoder-only Multimodal Large Language Model (MLLM) fine-tuned on visual instructions. They claim this yields better image-text alignment in feature space, which helps the diffusion model actually follow complex prompts. The architecture also uses a “dual-stream to single-stream” transformer design: video and text tokens start in separate lanes, then merge for multimodal fusion.
Key highlights
- 13B parameters trained with image-video joint modeling and a causal 3D VAE for spatial-temporal compression
- MLLM text encoder with decoder-only structure, not the typical CLIP/T5-XXL stack
- FP8 weights and multi-GPU sequence-parallel inference available for faster or leaner runs
- Integrated into HuggingFace Diffusers and ComfyUI; extensive community forks for GGUF, CPU-offloading, and acceleration
- Human evaluation claims it outperforms Runway Gen-3, Luma 1.6, and top Chinese closed models—though the README doesn’t detail evaluator methodology
Caveats
- The README is vague on exact VRAM requirements for full-precision inference; FP8 and community “GPU Poor” forks exist for a reason
- Human evaluation results are asserted without reproducible benchmark detail in the provided text
- Active development has moved forward: HunyuanVideo-1.5, I2V, avatar, and custom variants now live in separate repos
Verdict Worth a look if you’re building video generation pipelines and want a fully open weights baseline with broad ecosystem support. Skip if you need turnkey consumer hardware support without quantization hacks or if you require rigorous, reproducible benchmark documentation before trusting performance claims.
Frequently asked
- What is Tencent-Hunyuan/HunyuanVideo?
- A research team bet that scale and a repurposed MLLM text encoder could close the gap between open-source and proprietary video generation.
- Is HunyuanVideo open source?
- Yes — Tencent-Hunyuan/HunyuanVideo is an open-source project tracked on heatdrop.
- What language is HunyuanVideo written in?
- Tencent-Hunyuan/HunyuanVideo is primarily written in Python.
- How popular is HunyuanVideo?
- Tencent-Hunyuan/HunyuanVideo has 12.4k stars on GitHub.
- Where can I find HunyuanVideo?
- Tencent-Hunyuan/HunyuanVideo is on GitHub at https://github.com/Tencent-Hunyuan/HunyuanVideo.