StarTrail-org/LEANN
A vector index that never bothers to store your embeddings
LEANN is a personal RAG engine that claims to fit 60 million documents on a laptop by computing embeddings only when needed.
Velocity · 7d
+4.7
★ / day
Trend
→steady
star history
What it does
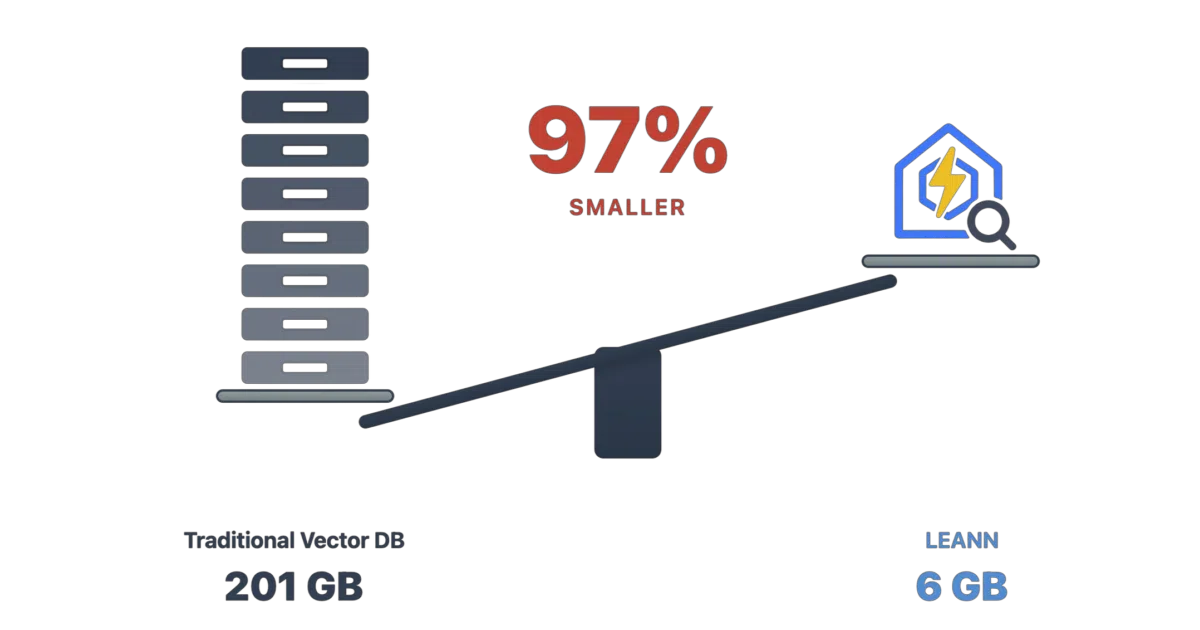
LEANN is a vector database and RAG framework built for personal hardware. It indexes files, emails, browser history, chat logs from WeChat or iMessage, and even live feeds via MCP servers, then answers questions using local or API-based language models. The project claims it can squeeze a 60-million-chunk corpus into about 6 GB of disk space—roughly 97% less than the 201 GB it says a conventional index would demand.
The interesting bit
Instead of storing every embedding, LEANN keeps a pruned similarity graph and recomputes vectors on demand through what it calls “graph-based selective recomputation” with “high-degree preserving pruning.” It treats dense embeddings as disposable intermediate results rather than precious cargo.
Key highlights
- Promises 97% storage savings by keeping a pruned graph and recomputing embeddings on demand rather than storing them.
- Runs fully offline with local models via HuggingFace, Ollama, or others, though it also supports OpenAI-compatible APIs.
- Ships with connectors for Apple Mail, WeChat, iMessage, ChatGPT and Claude histories, browser bookmarks, and Slack or Twitter via MCP.
- Exposes a native MCP service that plugs into Claude Code to replace its basic keyword search with semantic retrieval.
- Claims zero telemetry; the authors are polling users on whether to prioritize GPU acceleration next.
Caveats
- Building from source for the DiskANN backend requires a full C++ toolchain—Boost, Protobuf, OpenMP, and Intel MKL on some platforms—with documented workarounds for Ubuntu 20.04 and Windows.
- GPU acceleration is currently absent enough that the team is using a community survey to decide whether to build it.
Verdict
Good fit for developers who want to search years of personal data without cloud costs or privacy trade-offs. Less compelling if you need a managed vector database with mature operational tooling.
Frequently asked
- What is StarTrail-org/LEANN?
- LEANN is a personal RAG engine that claims to fit 60 million documents on a laptop by computing embeddings only when needed.
- Is LEANN open source?
- Yes — StarTrail-org/LEANN is open source, released under the MIT license.
- What language is LEANN written in?
- StarTrail-org/LEANN is primarily written in Python.
- How popular is LEANN?
- StarTrail-org/LEANN has 12.7k stars on GitHub and is currently holding steady.
- Where can I find LEANN?
- StarTrail-org/LEANN is on GitHub at https://github.com/StarTrail-org/LEANN.