SpeechColab/Leaderboard
A benchmarking zoo for speech recognition
Because comparing ASR models across YouTube clips, news broadcasts, and crosstalk comedy shouldn't require building your own pipeline from scratch.
Not currently ranked — collecting fresh signals.
star history
What it does
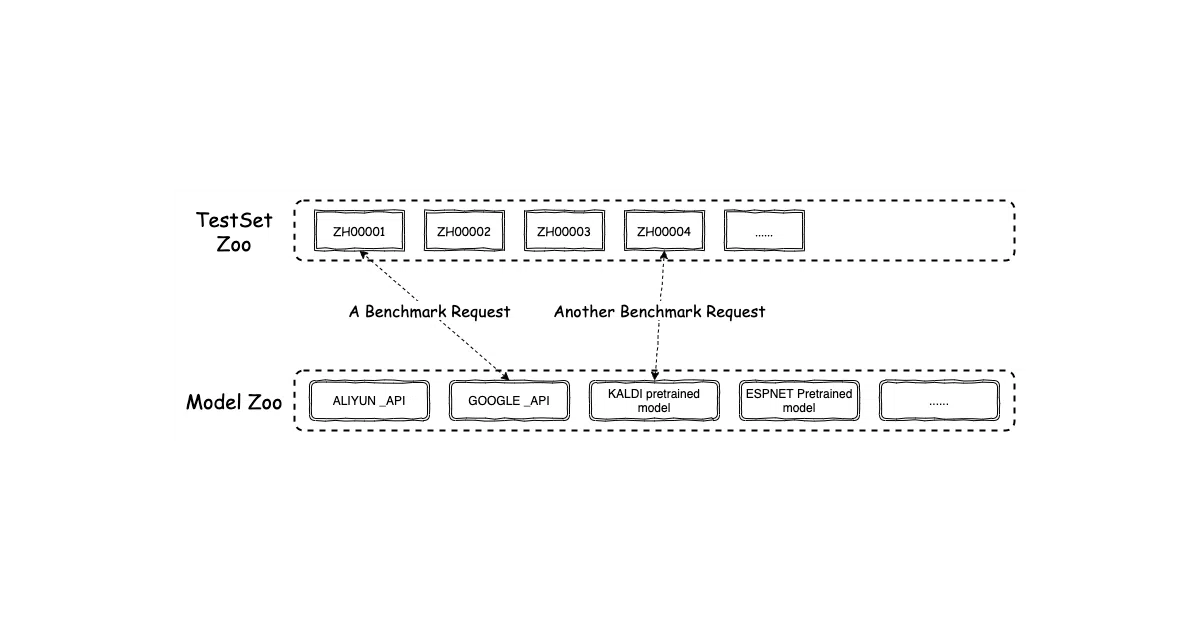
SpeechIO Leaderboard is a one-stop shop for benchmarking automatic speech recognition systems. It bundles curated test sets (academic and real-world), wrappers for dozens of commercial APIs and open-source models, and a standardized pipeline that runs data prep → recognition → scoring. The goal: anyone can reproduce someone else’s ASR numbers without reverse-engineering their setup.
The interesting bit
The real value is the “SpeechIO Test Sets” — 46 hand-curated Chinese audio collections scraped from YouTube, TV, podcasts, and livestreams, professionally transcribed, and rated 1–5 stars for difficulty. Want to know how your model handles a Sichuan-accented film, a livestreamed lipstick sale, or classical Chinese poetry? There’s a dataset for that. Some are locked behind a key icon, but the unlocked ones already cover more realistic scenarios than most academic benchmarks touch.
Key highlights
- 18+ academic test sets for English and Chinese (LibriSpeech, GigaSpeech, AISHELL, etc.)
- 46 custom Chinese test sets spanning news, gaming livestreams, stand-up comedy, regional accents, even hearing-impaired speech
- Pre-built model wrappers for major cloud APIs (Alibaba, Amazon, Baidu, Google, Microsoft, Tencent) and local open-source models
- Standardized pipeline: download → decode → score with WER/CER, no bespoke scripts needed
- Difficulty ratings and scenario tags make it easy to target weak spots
Caveats
- Roughly half the Chinese test sets are locked (marked with ✗); the README doesn’t explain how to unlock them
- The English model list in the README is truncated mid-table; full coverage is unclear without digging into the repo
- No visible English equivalent to the rich Chinese real-world test sets — the project is heavily China-centric
Verdict
Grab this if you’re building or choosing ASR systems for Chinese media, or if you need to sanity-check vendor API claims against a common baseline. Skip it if your focus is English-only and you’re already happy with LibriSpeech numbers that don’t reflect real-world noise.
Frequently asked
- What is SpeechColab/Leaderboard?
- Because comparing ASR models across YouTube clips, news broadcasts, and crosstalk comedy shouldn't require building your own pipeline from scratch.
- Is Leaderboard open source?
- Yes — SpeechColab/Leaderboard is an open-source project tracked on heatdrop.
- What language is Leaderboard written in?
- SpeechColab/Leaderboard is primarily written in Python.
- How popular is Leaderboard?
- SpeechColab/Leaderboard has 547 stars on GitHub.
- Where can I find Leaderboard?
- SpeechColab/Leaderboard is on GitHub at https://github.com/SpeechColab/Leaderboard.