SparkAudio/Spark-TTS
A Qwen2.5 that speaks: LLM-native text-to-speech
Spark-TTS treats voice synthesis as a language modeling problem, skipping the usual acoustic feature pipelines.
Not currently ranked — collecting fresh signals.
star history
What it does Spark-TTS is a text-to-speech system built entirely on Qwen2.5. Instead of chaining separate models for acoustic features and audio generation, it predicts speech tokens directly through the LLM and reconstructs audio from there. The repo provides inference code, a Gradio web UI, and a Triton/TensorRT-LLM runtime path for production deployment.
The interesting bit The “single-stream decoupled speech tokens” approach collapses the traditional TTS pipeline into one model. No flow matching, no vocoder juggling—just the LLM spitting out tokens that become waveform. The project also leans hard into zero-shot voice cloning with a gallery of celebrity demos that doubles as a responsible-use warning.
Key highlights
- Built on Qwen2.5; 0.5B parameter model available on Hugging Face
- Zero-shot voice cloning with cross-lingual and code-switching support (Chinese/English)
- Controllable generation: adjust gender, pitch, and speaking rate for virtual speakers
- Triton/TensorRT-LLM serving reference included; ~876ms latency at concurrency=1 on L20 GPU
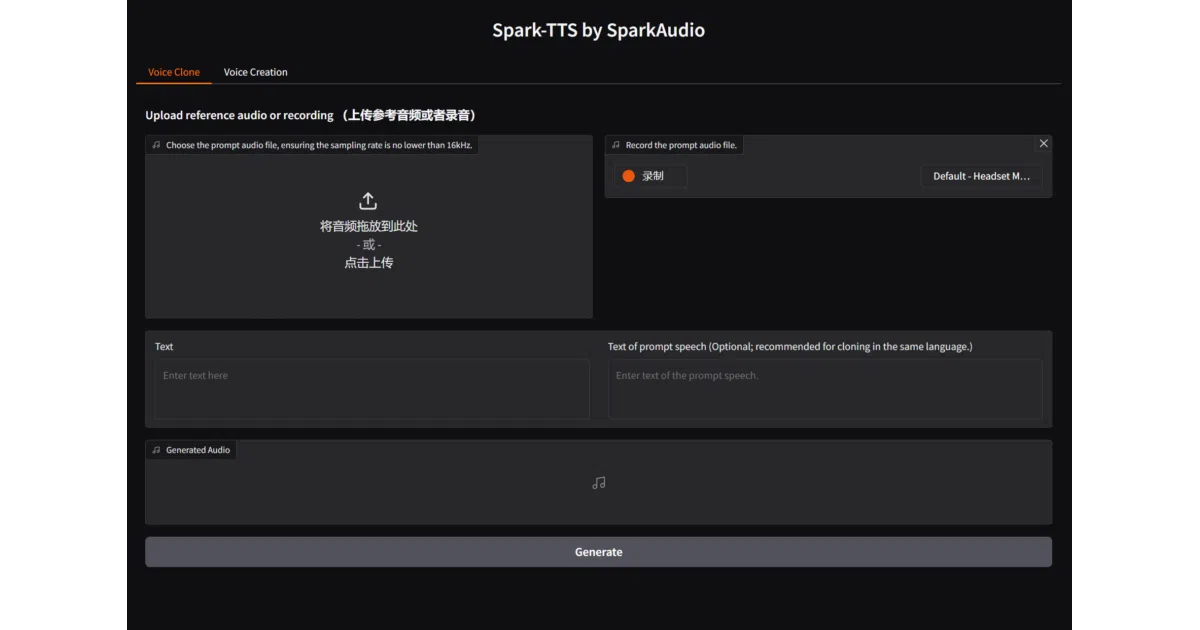
- Gradio web UI for voice cloning (upload or record reference) and voice creation
Caveats
- Training code and dataset (VoxBox) not yet released; this is inference-only for now
- Windows support exists only via community-contributed instructions in an issue thread
- The demo gallery includes public figures with an ethics disclaimer, but no technical guardrails are described
Verdict Worth a look if you’re building TTS into a product and want to test whether LLM-native synthesis beats your current pipeline. Skip it if you need training code today or run primarily on Windows without community patches.
Frequently asked
- What is SparkAudio/Spark-TTS?
- Spark-TTS treats voice synthesis as a language modeling problem, skipping the usual acoustic feature pipelines.
- Is Spark-TTS open source?
- Yes — SparkAudio/Spark-TTS is open source, released under the Apache-2.0 license.
- What language is Spark-TTS written in?
- SparkAudio/Spark-TTS is primarily written in Python.
- How popular is Spark-TTS?
- SparkAudio/Spark-TTS has 11k stars on GitHub.
- Where can I find Spark-TTS?
- SparkAudio/Spark-TTS is on GitHub at https://github.com/SparkAudio/Spark-TTS.