SamLynnEvans/Transformer
A Transformer you can actually read
A PyTorch seq2seq implementation that prioritizes clarity over state-of-the-art chasing.
Not currently ranked — collecting fresh signals.
star history
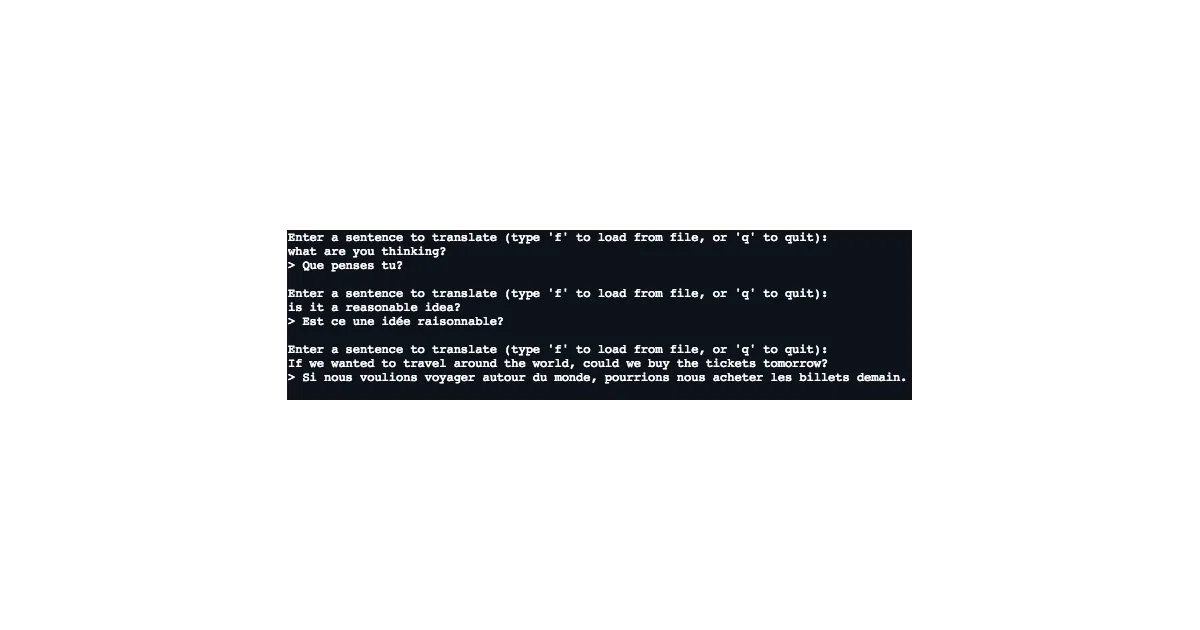
What it does
Trains a language translator from parallel text files using the original Transformer architecture. Feed it two newline-separated sentence files, pick your source and target languages from SpaCy’s seven supported options, and run train.py. After training, translate.py loads the saved weights and spits out translations.
The interesting bit
The README openly admits this hits 0.39 BLEU against a ~0.42 SOTA—not trying to wow you with benchmarks, but to teach you. The entire repo is essentially a companion to a detailed tutorial, making the code the product as much as the model. That’s rarer than it should be in ML repositories.
Key highlights
- Pure PyTorch implementation of the original Transformer paper
- Achieved 0.39 BLEU on Europarl after 4–5 days on a single 8GB GPU
- One-click FloydHub workspace for cloud training without dependency wrangling
- Configurable layers, heads, embedding dimensions, dropout, and cosine-annealed restarts
- Checkpointing by time interval rather than just epoch
Caveats
- No validation set or validation scores yet—listed explicitly as “still to add”
- SpaCy tokenizer limits you to seven European languages; no custom tokenizer hook
- README notes missing functionality for inspecting translations from training/validation sets
Verdict
Worth a look if you’re trying to understand how Transformers work under the hood, or need a hackable baseline for seq2seq experiments. Skip it if you need production-grade translation or broad language coverage out of the box.
Frequently asked
- What is SamLynnEvans/Transformer?
- A PyTorch seq2seq implementation that prioritizes clarity over state-of-the-art chasing.
- Is Transformer open source?
- Yes — SamLynnEvans/Transformer is open source, released under the Apache-2.0 license.
- What language is Transformer written in?
- SamLynnEvans/Transformer is primarily written in Python.
- How popular is Transformer?
- SamLynnEvans/Transformer has 1.4k stars on GitHub.
- Where can I find Transformer?
- SamLynnEvans/Transformer is on GitHub at https://github.com/SamLynnEvans/Transformer.