RightNow-AI/autokernel
Set an AI loose on your GPU kernels overnight, wake up to speedups
AutoKernel applies Andrej Karpathy's autoresearch loop to PyTorch models: profile, extract bottlenecks, let an agent iterate on Triton or CUDA C++ while you sleep.
Not currently ranked — collecting fresh signals.
star history
What it does
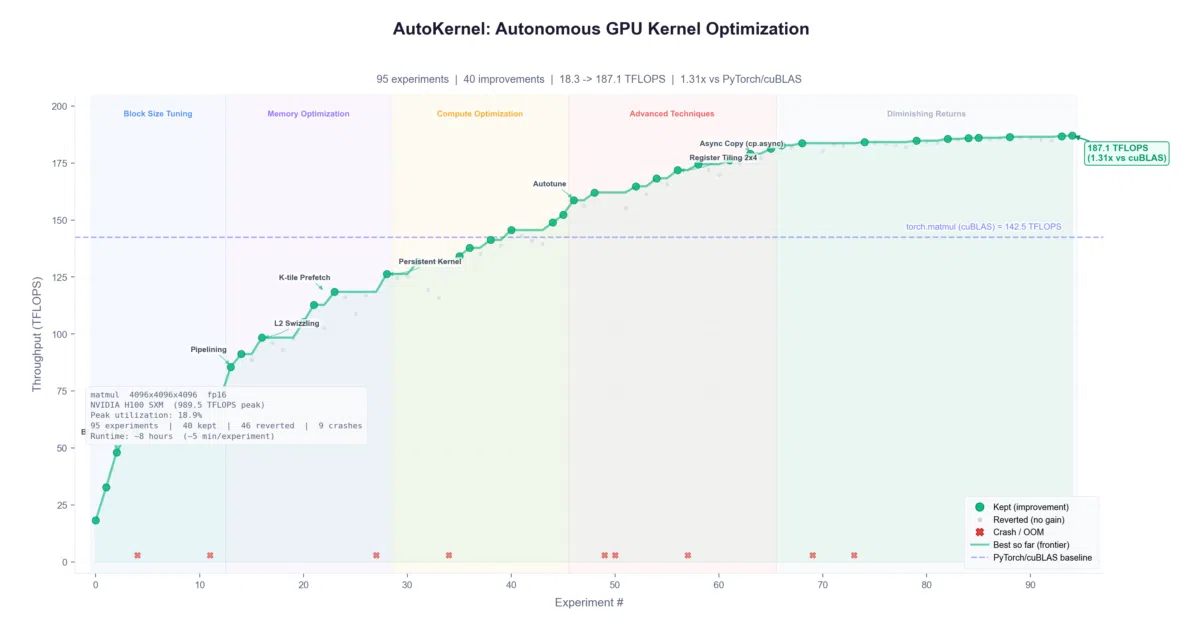
AutoKernel takes any PyTorch model, profiles it to find GPU kernel bottlenecks, extracts each one as a standalone Triton or CUDA C++ kernel, then hands it to an AI coding agent. The agent edits kernel.py, runs a fixed benchmark with five-stage correctness checks, and keeps or reverts the change. Rinse and repeat ~40 times per hour, ~320 overnight. The orchestrator uses Amdahl’s law to prioritize kernels that actually matter for end-to-end speedup, not just microbenchmark glory.
The interesting bit
The “research org code” lives in a single markdown file, program.md — a 6-tier optimization playbook, crash handling, and decision framework dense enough that the agent can run 10+ hours without human intervention. It’s essentially a human-readable runtime for autonomous GPU optimization, with TSV logging and git-friendly branches for each experiment.
Key highlights
- Dual backend: Triton for fast iteration, CUDA C++ for tensor-core-level performance; both share the same benchmark harness
- 9 supported kernel types: matmul, flash attention, RMSNorm, RoPE, fused MLP, and others covering modern transformer workloads
- Ships self-contained model definitions for GPT-2, LLaMA (7B), and BERT — no
transformerslibrary needed for basic profiling - KernelBench integration runs 50–300+ iterative experiments per problem vs. typical one-shot LLM generation
- Exports to HuggingFace Kernels Hub for one-line loading by other users
- AMD ROCm support (MI300X series) added in v1.3.0
Caveats
- Requires NVIDIA GPU (H100/A100/RTX 4090 tested); AMD support is newer and less battle-tested
- Each experiment takes ~90 seconds, so meaningful runs need hours of agent time and API credits
- The README notes Triton “regularly reaches 80-95% of cuBLAS” — no specific speedup numbers are claimed for end-to-end model runs
Verdict Worth a look if you’re already paying for Claude/Codex and have idle GPU nights. Less compelling if you need guaranteed speedups today — the agent might spend 300 experiments to find a 1.03x improvement on a marginal kernel. The KernelBench integration and HuggingFace export suggest the authors are building toward a community of shareable optimized kernels, not just a one-off tool.
Frequently asked
- What is RightNow-AI/autokernel?
- AutoKernel applies Andrej Karpathy's autoresearch loop to PyTorch models: profile, extract bottlenecks, let an agent iterate on Triton or CUDA C++ while you sleep.
- Is autokernel open source?
- Yes — RightNow-AI/autokernel is open source, released under the MIT license.
- What language is autokernel written in?
- RightNow-AI/autokernel is primarily written in Python.
- How popular is autokernel?
- RightNow-AI/autokernel has 1.5k stars on GitHub.
- Where can I find autokernel?
- RightNow-AI/autokernel is on GitHub at https://github.com/RightNow-AI/autokernel.