QwenLM/Qwen3-ASR
Speech recognition for 52 languages, plus a forced-alignment sidekick
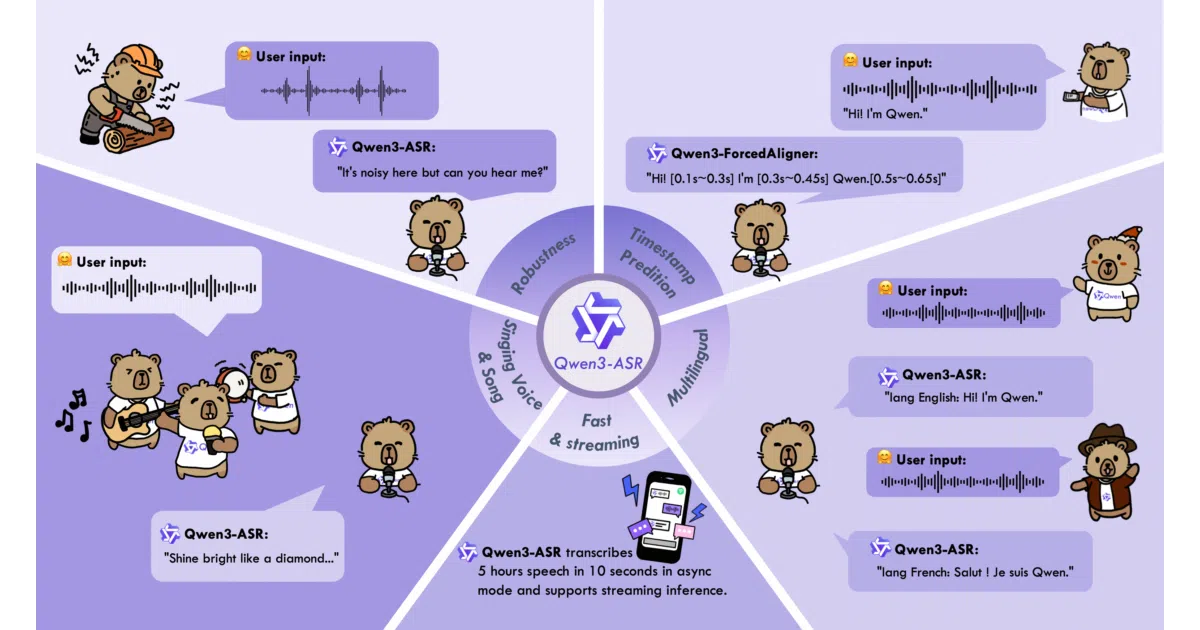
Alibaba's Qwen team released compact ASR models that transcribe 52 languages and dialects, including song and music-backed audio, alongside a standalone forced-alignment model for timestamping.
Not currently ranked — collecting fresh signals.
star history
What it does
Qwen3-ASR is a family of open-source speech recognition models from Alibaba’s Qwen team. The two main variants—1.7B and 0.6B parameters—transcribe and identify languages across 52 languages and Chinese dialects, including audio with singing or background music. A separate 0.6B non-autoregressive forced-alignment model predicts timestamps for text–speech pairs in 11 languages.
The interesting bit
The 1.7B model reportedly achieves state-of-the-art results among open-source ASR models and is competitive with proprietary commercial APIs. The 0.6B variant is tuned for throughput, with the project claiming it reaches 2000× throughput at a concurrency of 128—though the baseline for that multiplier is unspecified. The forced aligner is a distinct, non-autoregressive model rather than an afterthought bolted onto the main ASR.
Key highlights
- Supports 30 languages plus 22 Chinese dialects and English regional accents
- Handles speech, singing, and songs with background music in a single model
- Unified streaming and offline inference without swapping models
- Ships with an inference toolkit supporting vLLM batching, async serving, and timestamp prediction
- Available as a Python package with both transformers and vLLM backends, plus an official Docker image
Caveats
- FlashAttention 2 acceleration requires compatible hardware and only works with
float16orbfloat16weights - The vLLM backend can trigger Python multiprocessing
spawnerrors without proper entry-point guards
Verdict
Developers building multilingual voice apps or subtitle pipelines should look here, especially if they need a single model that handles both Mandarin dialects and music. If you only need English-only transcription on CPU, this is overkill.
Frequently asked
- What is QwenLM/Qwen3-ASR?
- Alibaba's Qwen team released compact ASR models that transcribe 52 languages and dialects, including song and music-backed audio, alongside a standalone forced-alignment model for timestamping.
- Is Qwen3-ASR open source?
- Yes — QwenLM/Qwen3-ASR is open source, released under the Apache-2.0 license.
- What language is Qwen3-ASR written in?
- QwenLM/Qwen3-ASR is primarily written in Python.
- How popular is Qwen3-ASR?
- QwenLM/Qwen3-ASR has 3k stars on GitHub.
- Where can I find Qwen3-ASR?
- QwenLM/Qwen3-ASR is on GitHub at https://github.com/QwenLM/Qwen3-ASR.