QuentinFuxa/WhisperLiveKit
Self-hosted speech-to-text that actually streams properly
Whisper isn't built for real-time chunks; this kit adds the buffering and incremental processing to make it work.
Not currently ranked — collecting fresh signals.
star history
What it does
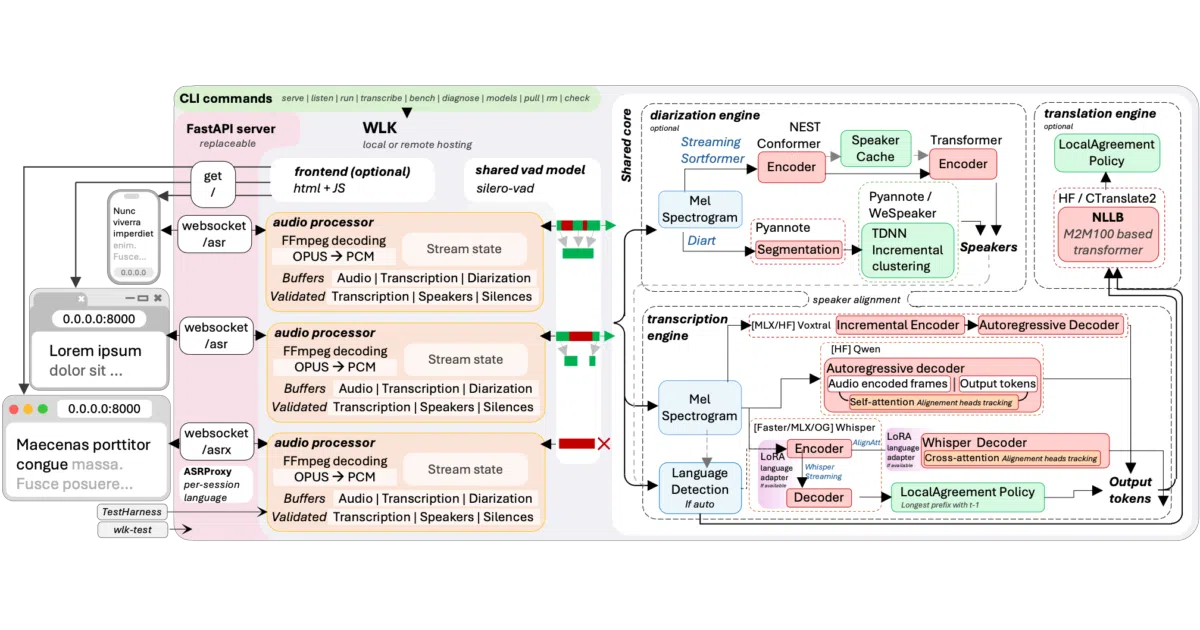
WhisperLiveKit runs a local speech-to-text server with low-latency streaming, speaker diarization, and optional real-time translation into 200 languages. It exposes OpenAI-compatible REST and Deepgram-compatible WebSocket APIs, plus a browser UI and Chrome extension for capturing web audio. You can also transcribe files or generate subtitles from the CLI without starting a server.
The interesting bit
The core problem: Whisper expects complete utterances, so naïvely feeding it audio chunks mangles words mid-syllable. The project layers several simultaneous-speech research policies—AlignAtt SimulStreaming, LocalAgreement, plus VAD-based buffering—to incrementally commit text only when the model is confident, keeping latency down without hallucinating retractions.
Key highlights
- Multiple backends: standard Whisper, Mistral’s 4B Voxtral model (better auto language detection), and Qwen3-ASR via vLLM
- Speaker diarization via Streaming Sortformer or Diart
- Simultaneous translation via distilled NLLB (200 languages)
wlkCLI handles model management, file transcription, subtitle export, and reproducible speed/accuracy benchmarks- Optional extras for Apple Silicon MLX, CUDA 12.9, CPU PyTorch, etc.
Caveats
- Several feature extras are mutually incompatible and require separate virtual environments (e.g.,
qwen3-vllmvscu129,voxtral-hfvsdiarization-sortformer) - Auto language detection with Whisper biases toward English; Voxtral is recommended for multilingual use
- The README notes a “not recommended” Diart diarization path still ships as an optional extra
Verdict
Worth a look if you need self-hosted, real-time transcription with speaker labels or live translation and don’t want to pay per-minute API fees. Skip it if you just need batch transcription on complete files—plain Whisper or faster-whisper is simpler.
Frequently asked
- What is QuentinFuxa/WhisperLiveKit?
- Whisper isn't built for real-time chunks; this kit adds the buffering and incremental processing to make it work.
- Is WhisperLiveKit open source?
- Yes — QuentinFuxa/WhisperLiveKit is open source, released under the Apache-2.0 license.
- What language is WhisperLiveKit written in?
- QuentinFuxa/WhisperLiveKit is primarily written in Python.
- How popular is WhisperLiveKit?
- QuentinFuxa/WhisperLiveKit has 10.5k stars on GitHub.
- Where can I find WhisperLiveKit?
- QuentinFuxa/WhisperLiveKit is on GitHub at https://github.com/QuentinFuxa/WhisperLiveKit.