Qihoo360/hbox
YARN for neural nets: Qihoo360's bridge from Hadoop to PyTorch
A scheduling layer that lets you run TensorFlow, PyTorch, and friends on the same cluster you already use for MapReduce.
Not currently ranked — collecting fresh signals.
star history
What it does
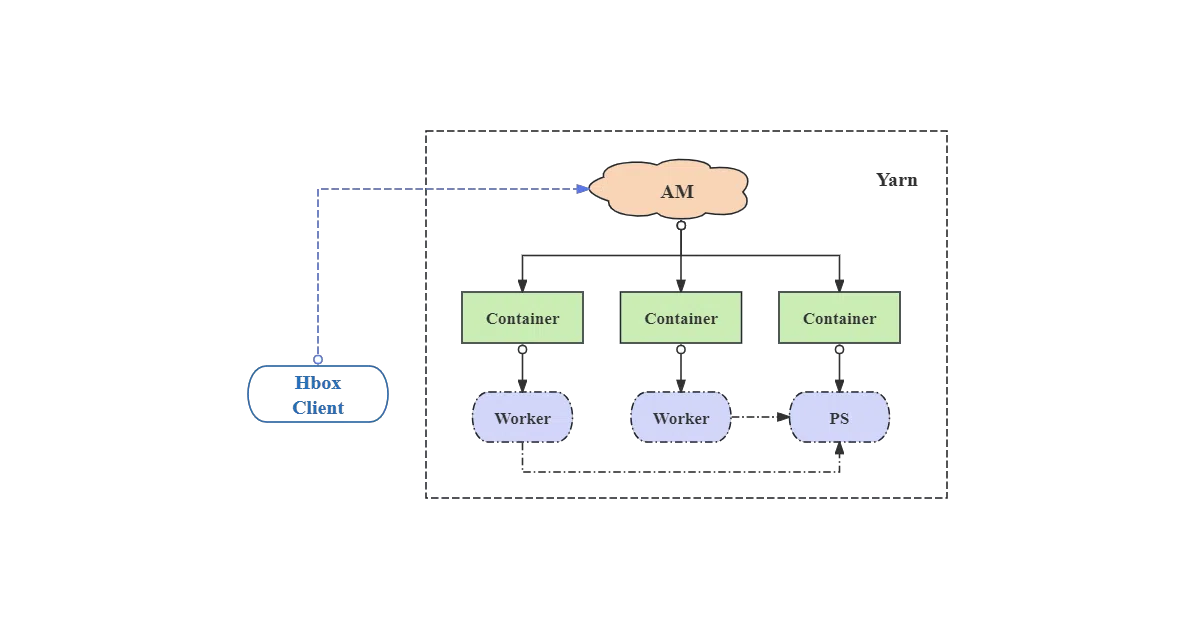
Hbox is a YARN application that schedules deep-learning jobs on Hadoop clusters. You submit a job with hbox-submit, and it spins up containers for workers and parameter servers, wires up distributed TensorFlow or MXNet automatically, and shuffles data through HDFS. It also handles standalone frameworks like PyTorch and Caffe without forcing you to rewrite your training script.
The interesting bit
The data-management layer borrows MapReduce’s InputFormat and OutputFormat concepts, so you can reuse existing Hadoop data-splitting logic for your neural-net pipeline. It also supports three input strategies—download to local, stream from HDFS, or pipe through InputFormat—depending on whether your bottleneck is network, disk, or memory.
Key highlights
- Supports TensorFlow, MXNet, PyTorch, Keras, XGBoost, Horovod, OpenMPI, and others
- GPU scheduling requires Hadoop 3.1+; works with Hadoop 2.6 through 3.2 for CPU
- Docker support and REST API for management
- Built-in TensorBoard linking and intermediate model saving to HDFS
- Automatic ClusterSpec construction for distributed TensorFlow
Caveats
- Documentation is sparse in English; most detail lives in Chinese docs
- Compilation produces a
1.1distribution while badges claim1.4, so version alignment is unclear - CentOS 7.2 is the stated target OS, which may or may not matter for modern deployments
Verdict
Worth a look if you’re stuck with a Hadoop estate and want to run ML without building a separate Kubernetes cluster. Skip it if you’re already on a cloud-native stack—this is glue code for a specific migration problem, and it knows it.
Frequently asked
- What is Qihoo360/hbox?
- A scheduling layer that lets you run TensorFlow, PyTorch, and friends on the same cluster you already use for MapReduce.
- Is hbox open source?
- Yes — Qihoo360/hbox is open source, released under the Apache-2.0 license.
- What language is hbox written in?
- Qihoo360/hbox is primarily written in Java.
- How popular is hbox?
- Qihoo360/hbox has 1.7k stars on GitHub.
- Where can I find hbox?
- Qihoo360/hbox is on GitHub at https://github.com/Qihoo360/hbox.