Picovoice/speech-to-text-benchmark
A neutral referee for speech-to-text bragging rights
Picovoice built a benchmarking framework that pits cloud APIs, open-source models, and its own engines against the same audio datasets.
Not currently ranked — collecting fresh signals.
star history
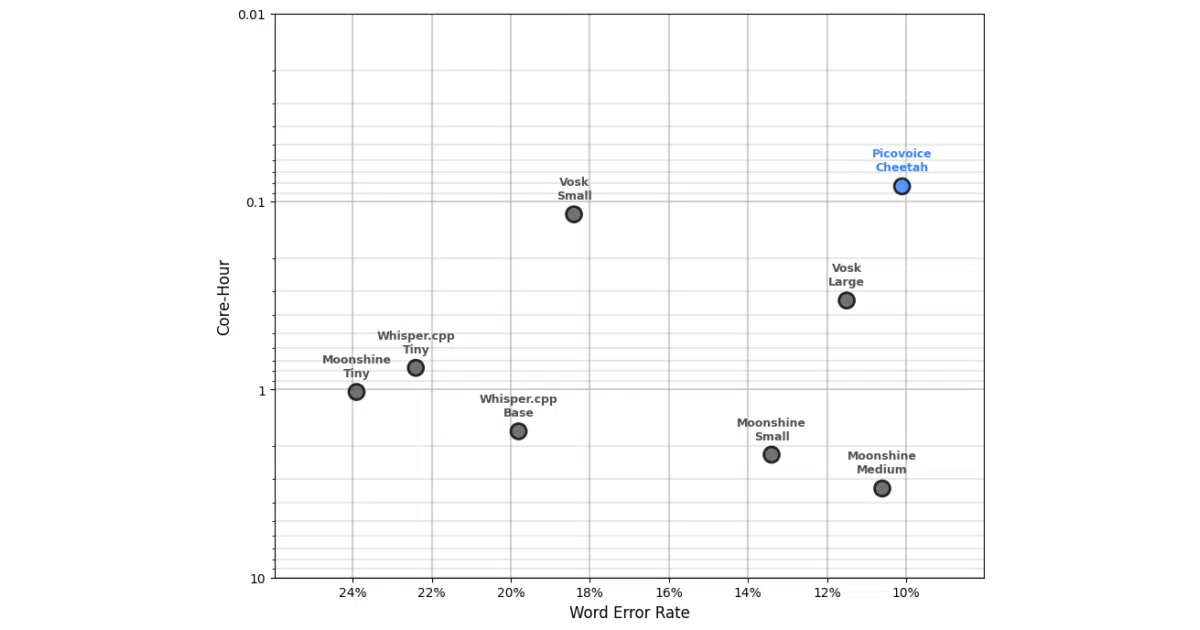
What it does This repo runs the same speech-to-text workloads across ten engines—cloud giants (Amazon, Google, Azure, IBM), open-source favorites (Whisper, Whisper.cpp, Vosk, Moonshine), and Picovoice’s own Cheetah and Leopard—then scores them on identical metrics. It supports seven languages and six public datasets including LibriSpeech, Common Voice, and FLEURS.
The interesting bit Most benchmarks are blog-post marketing dressed in charts. This one at least forces every engine through the same pipeline, measuring not just word error rate but punctuation accuracy, CPU core-hours, model size, and streaming latency. The “punctuation error rate” metric is a nice touch—periods and question marks matter more than WER alone admits.
Key highlights
- Evaluates WER, PER (punctuation error rate), core-hour efficiency, model size, and word emission latency
- Supports streaming and batch modes where engines offer both
- Covers EN, FR, DE, ES, IT, PT_BR, PT_PT across six standard datasets
- Includes alignment-generation tooling for latency measurement
- Single Python script per engine; Ubuntu 22.04 is the tested platform
Caveats
- Picovoice’s own engines are in the mix; the framework is maintained by Picovoice
- Some engines are English-only (IBM Watson, Moonshine, Vosk)
- Cloud engines require live credentials and incur real costs to benchmark
- Core-hour and model size metrics are omitted for cloud APIs, making apples-to-apples efficiency comparisons incomplete
Verdict Useful if you’re choosing between STT engines and need numbers beyond vendor datasheets. Less useful if you want fully automated, cost-free runs—cloud credentials and dataset downloads are on you.
Frequently asked
- What is Picovoice/speech-to-text-benchmark?
- Picovoice built a benchmarking framework that pits cloud APIs, open-source models, and its own engines against the same audio datasets.
- Is speech-to-text-benchmark open source?
- Yes — Picovoice/speech-to-text-benchmark is open source, released under the Apache-2.0 license.
- What language is speech-to-text-benchmark written in?
- Picovoice/speech-to-text-benchmark is primarily written in Python.
- How popular is speech-to-text-benchmark?
- Picovoice/speech-to-text-benchmark has 696 stars on GitHub.
- Where can I find speech-to-text-benchmark?
- Picovoice/speech-to-text-benchmark is on GitHub at https://github.com/Picovoice/speech-to-text-benchmark.