PacificAI/langtest
One-liner stress tests for language models
LangTest wraps 60+ model evaluation patterns into a single Python call, from toxicity checks to sycophancy detection.
Not currently ranked — collecting fresh signals.
star history
What it does
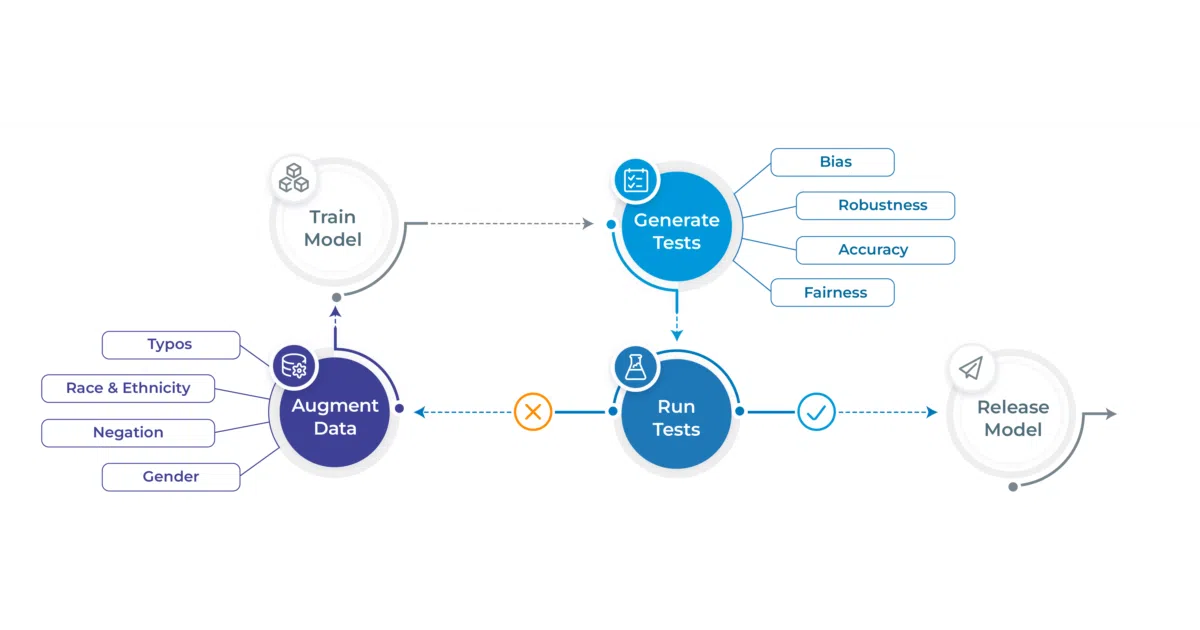
LangTest is a Python toolkit that generates, runs, and reports on model tests through a Harness object. You instantiate it with a task (NER, QA, summarization, etc.) and a model source—Hugging Face, OpenAI, Azure, Spark NLP—then call generate().run().report() to surface failures in robustness, bias, fairness, or factuality. It also bundles curated benchmark datasets and can augment training data for some model types based on test results.
The interesting bit The breadth is the point: instead of cobbling together separate tools for toxicity, sycophancy, clinical safety, and stereotype bias, LangTest treats them as test categories in the same harness. That makes it feasible to run a battery of checks on a new model without writing custom evaluation code for each failure mode.
Key highlights
- 60+ test types accessible through one API call
- Supports both traditional NLP (NER, text classification, translation) and LLM evaluation (OpenAI, Cohere, AI21, Azure-OpenAI)
- Built-in benchmark datasets for QA, summarization, and bias testing
- Automated data augmentation for select models based on test failures
- Integrates with MLflow for experiment tracking
Caveats
- The “one line of code” claim is technically true for the happy path, but real evaluation likely requires tuning test configurations and interpreting category-specific reports
- Data augmentation is noted as “for select models”—which ones is not specified in the README
- 559 stars suggests adoption is still modest; longevity depends on Pacific AI / John Snow Labs continued maintenance
Verdict Worth a look if you’re shipping LLMs or NLP pipelines and need a structured way to check for bias, safety, and robustness without building an evaluation framework from scratch. Less useful if you already have bespoke eval infrastructure or need deep customization beyond the built-in test catalog.
Frequently asked
- What is PacificAI/langtest?
- LangTest wraps 60+ model evaluation patterns into a single Python call, from toxicity checks to sycophancy detection.
- Is langtest open source?
- Yes — PacificAI/langtest is open source, released under the Apache-2.0 license.
- What language is langtest written in?
- PacificAI/langtest is primarily written in Python.
- How popular is langtest?
- PacificAI/langtest has 563 stars on GitHub.
- Where can I find langtest?
- PacificAI/langtest is on GitHub at https://github.com/PacificAI/langtest.