OryxProject/oryx
Lambda architecture for ML, circa 2015, still running on Hadoop clusters
A Java framework that wires Spark and Kafka into end-to-end machine learning pipelines for teams already living in the Hadoop ecosystem.
Not currently ranked — collecting fresh signals.
star history
What it does Oryx 2 implements the lambda architecture — batch layer plus speed layer — using Apache Spark and Apache Kafka, with a specific tilt toward real-time, large-scale machine learning. It doubles as both a framework for custom applications and a set of ready-made pipelines for collaborative filtering, classification, regression, and clustering. You configure, deploy to your Hadoop cluster, and hit REST endpoints.
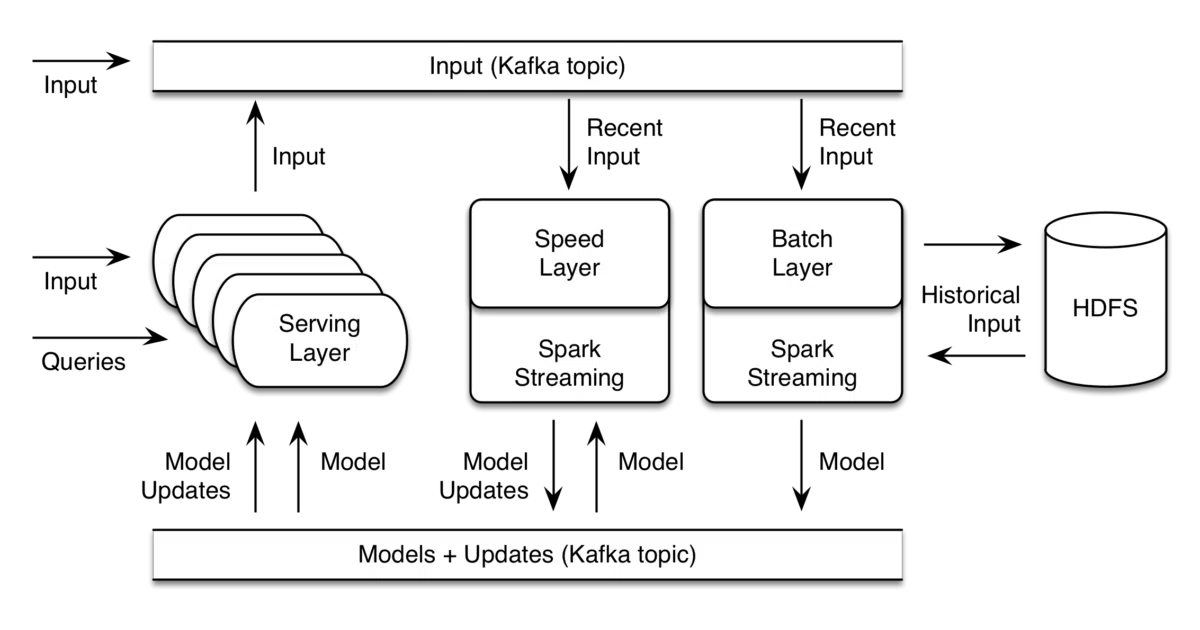
The interesting bit The project tries to spare you from hand-rolling the plumbing between streaming ingestion, model training, and serving. The architecture diagram is doing a lot of heavy lifting here — it shows a three-layer stack (batch, speed, serving) wired together with Kafka topics and Spark jobs, which was a genuinely useful abstraction when the lambda architecture was in vogue.
Key highlights
- End-to-end applications included: collaborative filtering, clustering, classification, regression
- Built on Spark and Kafka, deployed to Hadoop clusters
- REST API for model serving and predictions
- Also functions as a framework for building custom ML applications
- Java-based, with module structure documented via SourceSpy
Caveats
- Documentation and releases point to oryx.io, which may or may not still be actively maintained (the README references Travis CI and Coverity badges without context on current status)
- “Real-time” here means lambda-architecture real-time, not sub-second; latency characteristics aren’t quantified in the README
- The Hadoop-centric deployment model assumes a cluster setup that many teams have moved away from
Verdict Worth a look if you’re maintaining legacy Hadoop infrastructure and need collaborative filtering or clustering without rewriting pipelines. Probably not your starting point if you’re on cloud-native streaming or modern feature stores.
Frequently asked
- What is OryxProject/oryx?
- A Java framework that wires Spark and Kafka into end-to-end machine learning pipelines for teams already living in the Hadoop ecosystem.
- Is oryx open source?
- Yes — OryxProject/oryx is open source, released under the Apache-2.0 license.
- What language is oryx written in?
- OryxProject/oryx is primarily written in Java.
- How popular is oryx?
- OryxProject/oryx has 1.8k stars on GitHub.
- Where can I find oryx?
- OryxProject/oryx is on GitHub at https://github.com/OryxProject/oryx.