NVIDIA/Model-Optimizer
NVIDIA's kitchen-sink toolkit for shrinking AI models
A single library that quantizes, prunes, distills, and speculatively decodes models so they actually fit in production.
Velocity · 7d
+7.1
★ / day
Trend
↘cooling
star history
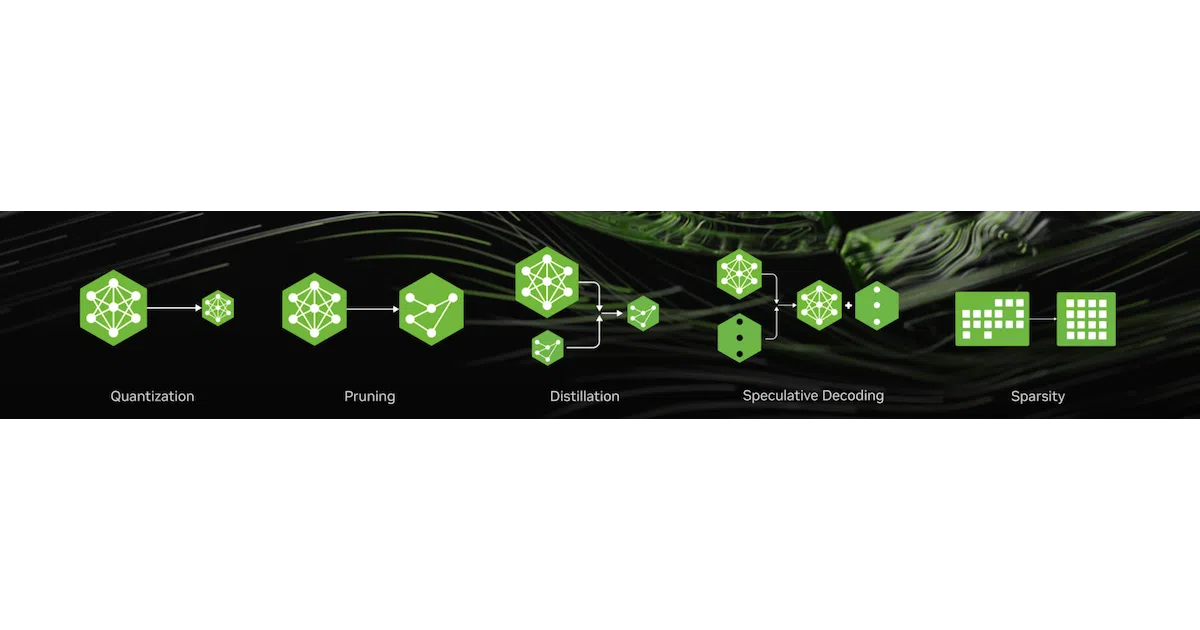
What it does Model Optimizer (formerly TensorRT Model Optimizer) is NVIDIA’s open-source Python library for compressing deep-learning models through a buffet of techniques: post-training quantization, quantization-aware training, pruning, distillation, neural architecture search, speculative decoding, and sparsity. It accepts Hugging Face, PyTorch, or ONNX models and exports optimized checkpoints ready for TensorRT-LLM, TensorRT, vLLM, or SGLang.
The interesting bit The value isn’t any single technique—it’s the composition. The library lets you stack methods (pruning + distillation + FP8 quantization, for example) and integrates with Megatron-Bridge, Megatron-LM, and Hugging Face Accelerate for training-aware workflows. Recent customer stories show real compression: Domyn took a 355B model down to 260B; Bielik.AI shrank a 7B model by 33% while keeping 90% quality.
Key highlights
- Supports NVFP4 and FP8 quantization, including ready-made quantized checkpoints for Llama 3/4, DeepSeek-R1, and Nemotron-3-Super on Hugging Face
- “Puzzletron” algorithm for heterogeneous pruning and NAS across LLMs and VLMs
- Experimental vLLM deployment path alongside first-class TensorRT-LLM integration
- Pre-installed in NVIDIA’s PyTorch, NeMo, and TensorRT-LLM containers
- Apache 2.0 licensed; available via PyPI as
nvidia-modelopt
Caveats
- The README’s “2x–4x compression” claim for PTQ lacks specific benchmarks or model references
- vLLM deployment is explicitly marked experimental
- Heavy NVIDIA ecosystem tilt; AMD or Intel GPU support is unclear
Verdict Worth a look if you’re already in the NVIDIA stack and need to squeeze inference latency or memory. Skip it if you need cross-vendor portability or lightweight, framework-agnostic tooling.
Frequently asked
- What is NVIDIA/Model-Optimizer?
- A single library that quantizes, prunes, distills, and speculatively decodes models so they actually fit in production.
- Is Model-Optimizer open source?
- Yes — NVIDIA/Model-Optimizer is open source, released under the Apache-2.0 license.
- What language is Model-Optimizer written in?
- NVIDIA/Model-Optimizer is primarily written in Python.
- How popular is Model-Optimizer?
- NVIDIA/Model-Optimizer has 3.3k stars on GitHub and is currently cooling off.
- Where can I find Model-Optimizer?
- NVIDIA/Model-Optimizer is on GitHub at https://github.com/NVIDIA/Model-Optimizer.