NVIDIA-Merlin/NVTabular
ETL that outruns the model training
A GPU-accelerated preprocessing library that turns week-long tabular data pipelines into minutes.
Not currently ranked — collecting fresh signals.
star history
What it does
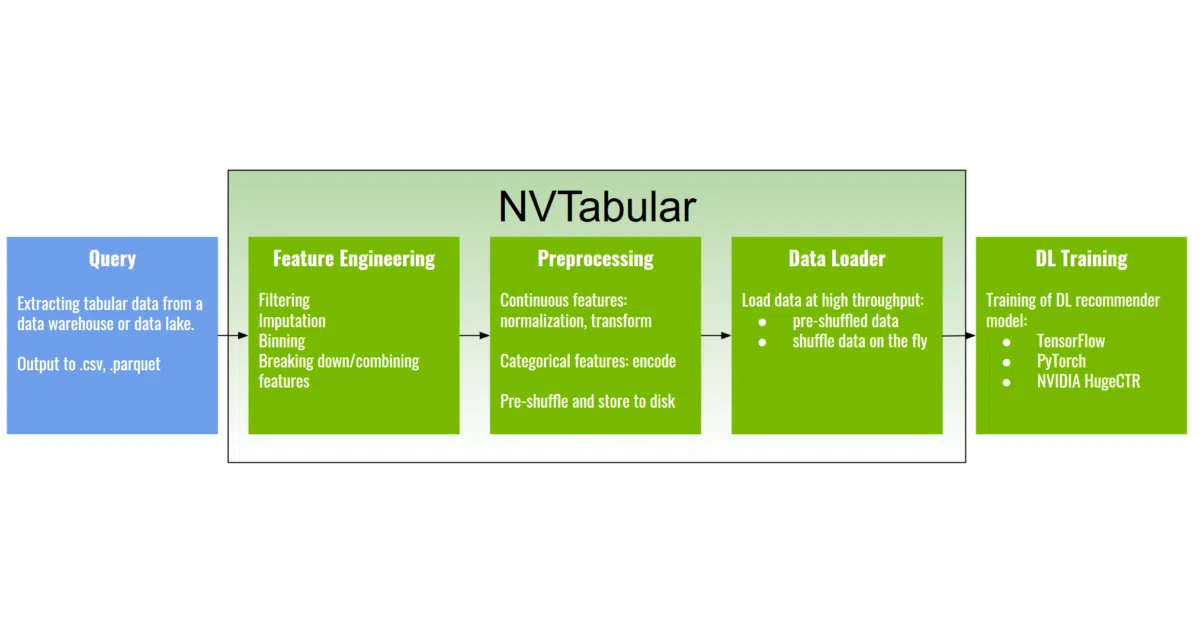
NVTabular is a feature engineering and preprocessing library for tabular data, built specifically for recommender systems at terabyte scale. It sits on top of RAPIDS Dask-cuDF to run ETL on NVIDIA GPUs, and it plugs into the broader NVIDIA Merlin stack—including HugeCTR, Merlin Models, and Triton Inference Server—for end-to-end GPU acceleration.
The interesting bit
The performance claims are almost lopsided: on the Criteo 1TB dataset, a single V100 GPU finishes preprocessing in 13 minutes; an 8-GPU DGX-1 cluster cuts that to 3 minutes. The README notes that a NumPy-based ETL script for a related workflow took over five days. The speedup isn’t from algorithmic magic—it’s from moving the same operations to GPU and parallelizing with Dask.
Key highlights
- Out-of-core processing: handles datasets larger than GPU or CPU memory via Dask-cuDF partitioning
- High-level API abstracts the “how” so you focus on the “what”
- Integrates with Triton Inference Server to replay training-time transformations at inference
- CPU fallback available via
pip install, though GPU mode requires Conda or Docker - Pre-built Docker images bundle TensorFlow, PyTorch, or HugeCTR variants
Caveats
- GPU support is Linux/WSL only; Pascal or newer required
pip installdrops you to CPU-only mode and may need manual dependency wrangling- Python 3.7+ baseline feels slightly dated
Verdict
Worth a look if you’re building large-scale recommenders and your preprocessing is the bottleneck. Skip it if your data fits in RAM and your pandas pipeline is already fast enough, or if you’re not on NVIDIA hardware.
Frequently asked
- What is NVIDIA-Merlin/NVTabular?
- A GPU-accelerated preprocessing library that turns week-long tabular data pipelines into minutes.
- Is NVTabular open source?
- Yes — NVIDIA-Merlin/NVTabular is open source, released under the Apache-2.0 license.
- What language is NVTabular written in?
- NVIDIA-Merlin/NVTabular is primarily written in Python.
- How popular is NVTabular?
- NVIDIA-Merlin/NVTabular has 1.1k stars on GitHub.
- Where can I find NVTabular?
- NVIDIA-Merlin/NVTabular is on GitHub at https://github.com/NVIDIA-Merlin/NVTabular.