Minqi824/ADBench
98,436 experiments say your favorite anomaly detector probably isn't the best
A NeurIPS 2022 benchmark that runs 30 algorithms across 57 datasets to settle which anomaly detection methods actually work—and under what conditions they fall apart.
Not currently ranked — collecting fresh signals.
star history
What it does
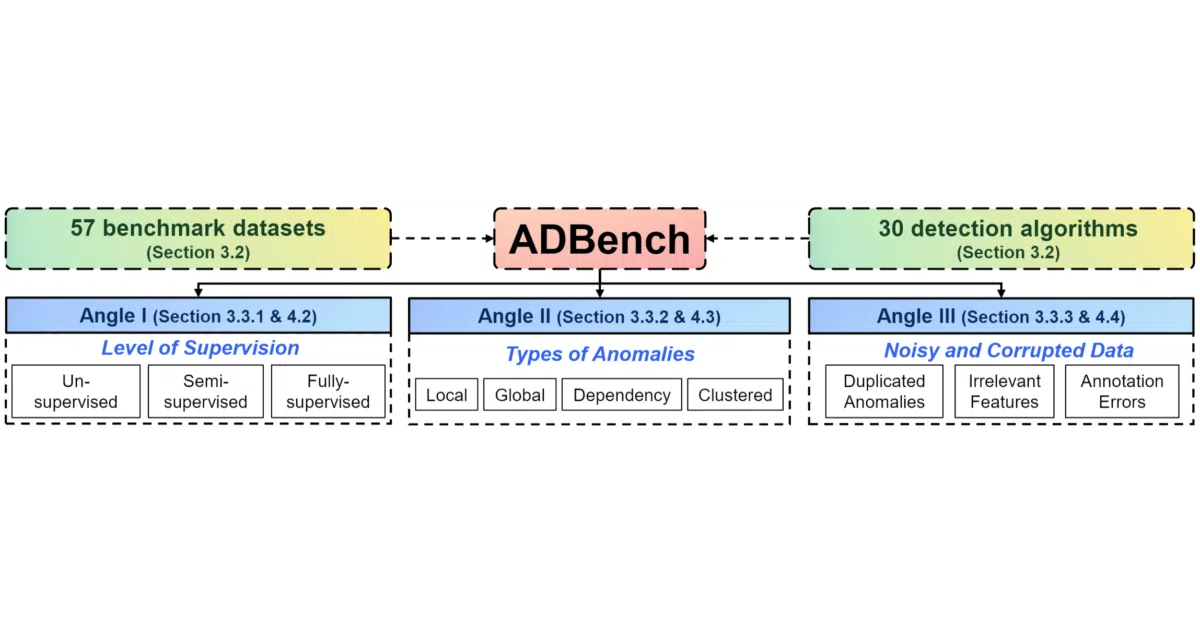
ADBench is a systematic testbed for tabular anomaly detection. It runs 30 algorithms (14 unsupervised, 7 semi-supervised, 9 supervised) through 98,436 experiments on 57 datasets, measuring performance across three angles: how much supervision helps, how different anomaly types trip up models, and how algorithms handle corrupted or noisy data. You can install it via pip install adbench, download datasets from a remote repo, and benchmark your own method with a few lines of Python.
The interesting bit The big surprise: no single unsupervised algorithm statistically dominates the others. Even weirder, with just 1% labeled anomalies, semi-supervised methods often beat the best unsupervised approach—yet in controlled settings, the right unsupervised method for a specific anomaly type can outperform fully supervised ones. The lesson is less “use X” and more “it depends, so test it.”
Key highlights
- 57 datasets in unified
.npzformat, including 10 new CV/NLP-derived sets with pretrained embeddings - Three experimental angles: supervision level, anomaly type (local/global/dependency/cluster), and data corruption (duplicated anomalies, irrelevant features, label contamination)
RunPipelineclass handles parallel execution and auto-exports results to CSV- Custom algorithm support: drop your model into the
Customizedbaseline template - Maintained by the PyOD/TODS/PyGOD authors, so the ecosystem integration is real
Caveats
- Datasets must be downloaded separately from the GitHub repo (or jihulab for mainland China users); not bundled in the pip package
- The README’s dependency list is commented out, so you’ll need to check
guidance.ipynbor source code for actual requirements - Multi-class datasets like CIFAR10 require special naming conventions (
number_data_class.npz)
Verdict Worth your time if you’re publishing anomaly detection research or choosing a production model and don’t want to rely on folklore. Skip it if you already know your data is clean, your anomalies are purely local, and you’ve sworn a blood oath to a single algorithm.
Frequently asked
- What is Minqi824/ADBench?
- A NeurIPS 2022 benchmark that runs 30 algorithms across 57 datasets to settle which anomaly detection methods actually work—and under what conditions they fall apart.
- Is ADBench open source?
- Yes — Minqi824/ADBench is open source, released under the BSD-2-Clause license.
- What language is ADBench written in?
- Minqi824/ADBench is primarily written in Python.
- How popular is ADBench?
- Minqi824/ADBench has 1k stars on GitHub.
- Where can I find ADBench?
- Minqi824/ADBench is on GitHub at https://github.com/Minqi824/ADBench.