Lightning-AI/pytorch-lightning
PyTorch's missing scaffolding: write the model, skip the boilerplate
A thin, opinionated layer over PyTorch that automates distributed training, mixed precision, and logging without touching your model code.
Not currently ranked — collecting fresh signals.
star history
What it does
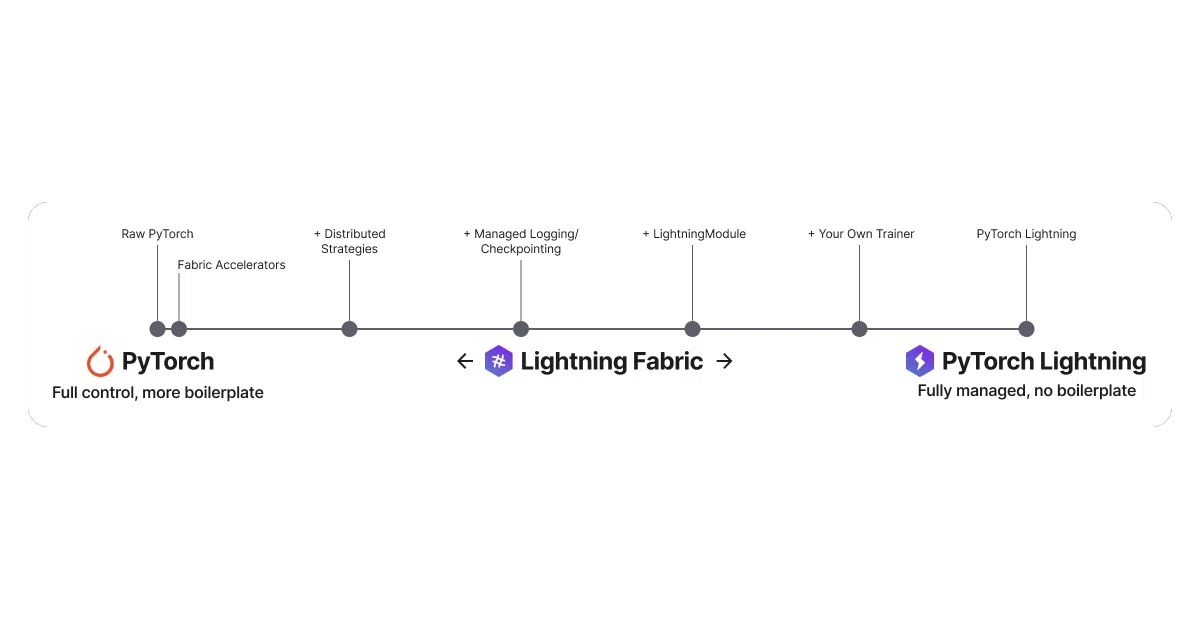
PyTorch Lightning is an organizational wrapper around PyTorch. You subclass LightningModule to define your model, training step, and optimizer; the Trainer then handles backpropagation, device placement, mixed precision, multi-GPU, and distributed training. The pitch is that scaling from a single CPU to 10,000 GPUs requires zero changes to your core model code.
The interesting bit The project explicitly offers a dial, not a wall. If you want full abstraction, use PyTorch Lightning. If you want to hand-roll distributed logic but still skip some boilerplate, Lightning Fabric gives you “expert control” at a lower level. The README’s own analogy: PyTorch is JavaScript, Lightning is React.
Key highlights
LightningModulebundles model, loss, and optimizer configuration into one subclass, keeping research code separate from engineering glue.Trainer.fit()automatically handles mixed precision, gradient clipping, checkpointing, and distributed backends.- Lightning Fabric provides a lower-level API for PyTorch experts who want granular control without starting from scratch.
- Pre-built examples cover LLM fine-tuning (Llama 3.1 8B), diffusion models, audio generation, and standard vision tasks.
- Optional hosted platform (Lightning Cloud) offers one-command GPU access with autoscaling.
Caveats
- The “zero code changes” scaling claim assumes you wrote your model in Lightning’s structure to begin with; migrating existing PyTorch loops still takes work.
- The README is heavy on marketing for Lightning Cloud and LitServe; the core framework documentation is linked but not shown inline.
Verdict Worth a look if you’re tired of rewriting distributed training scaffolding for every new project. Skip it if you already have a battle-tested training loop you don’t want to refactor, or if you need something more framework-agnostic than PyTorch-specific.
Frequently asked
- What is Lightning-AI/pytorch-lightning?
- A thin, opinionated layer over PyTorch that automates distributed training, mixed precision, and logging without touching your model code.
- Is pytorch-lightning open source?
- Yes — Lightning-AI/pytorch-lightning is open source, released under the Apache-2.0 license.
- What language is pytorch-lightning written in?
- Lightning-AI/pytorch-lightning is primarily written in Python.
- How popular is pytorch-lightning?
- Lightning-AI/pytorch-lightning has 31.2k stars on GitHub.
- Where can I find pytorch-lightning?
- Lightning-AI/pytorch-lightning is on GitHub at https://github.com/Lightning-AI/pytorch-lightning.