Kyubyong/tacotron
Tacotron in TensorFlow: when your model learns to speak, but only after you do
A heavily documented, battle-worn reimplementation of Google's end-to-end TTS model that reveals how finicky attention mechanisms really are.
Not currently ranked — collecting fresh signals.
star history
What it does This repo implements Google’s Tacotron paper in TensorFlow 1.x, converting text directly to mel spectrograms without traditional pipeline stages. It trains on three datasets: the standard LJ Speech (24 hours), Nick Offerman’s audiobooks (18 hours, to test limited data), and a hand-aligned World English Bible corpus (72 hours). Pretrained checkpoints and generated samples are provided.
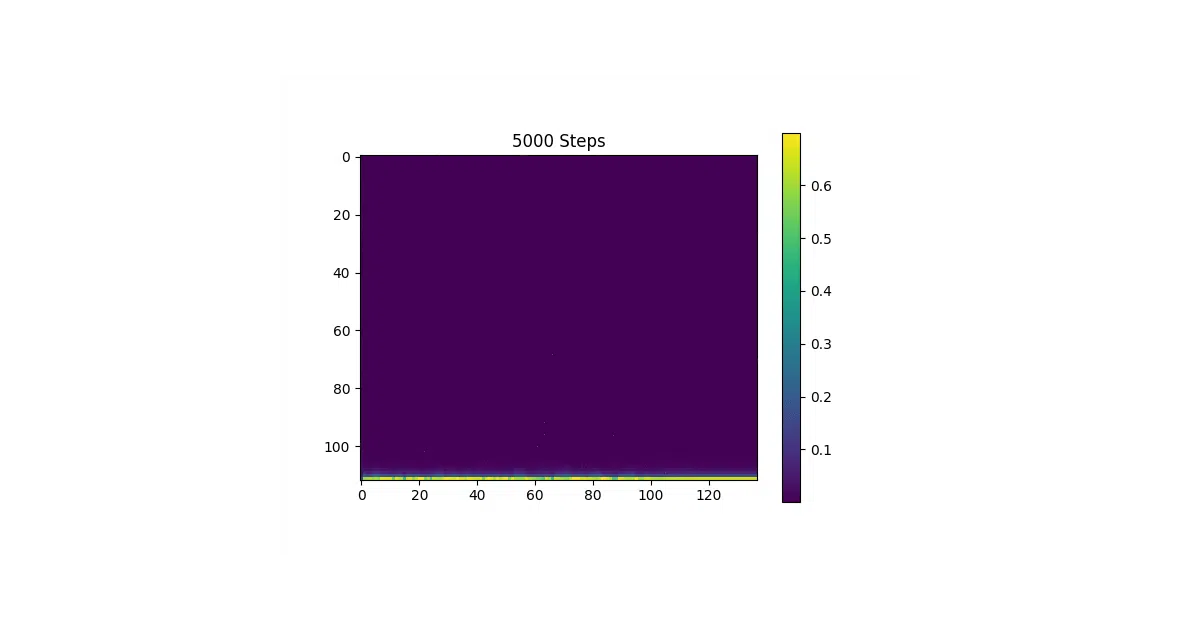
The interesting bit The README is unusually candid about failure modes. The authors initially misread the paper’s “reduction factor” and spent ages predicting non-sequential frames before realizing their decoder scheme was nonsense. They also discovered that attention alignment can suddenly collapse mid-training — linear plots devolve into chaos, loss spikes, and you’re effectively dead in the water. The fix: revert to an earlier checkpoint, because recovery is “unlikely.”
Key highlights
- Includes Noam warmup, gradient clipping, and bucketed batches (deviations from the original paper)
- Provides attention monitoring via animated plots to catch training death early
- Learning rate 0.001 vs 0.002 was the difference between “discernable words” and exploding loss
- Pretrained 200k-step models available via Dropbox for LJ Speech and WEB datasets
- Referenced in subsequent research papers, including a Stanford CS224S project
Caveats
- TensorFlow >= 1.3 dates this firmly to the TF 1.x era; porting required for modern stacks
- 200k steps is explicitly noted as “not enough for the best performance”
- No vocoder included — you’ll need Griffin-Lim or a separate network to get actual audio
Verdict Worth studying if you’re implementing attention-based sequence models and want to learn from someone else’s debugging scars. Skip if you need a production TTS system today; this is a research artifact with educational value, not a shipping product.
Frequently asked
- What is Kyubyong/tacotron?
- A heavily documented, battle-worn reimplementation of Google's end-to-end TTS model that reveals how finicky attention mechanisms really are.
- Is tacotron open source?
- Yes — Kyubyong/tacotron is open source, released under the Apache-2.0 license.
- What language is tacotron written in?
- Kyubyong/tacotron is primarily written in Python.
- How popular is tacotron?
- Kyubyong/tacotron has 1.8k stars on GitHub.
- Where can I find tacotron?
- Kyubyong/tacotron is on GitHub at https://github.com/Kyubyong/tacotron.