IDEA-Research/DINO-X-API
One API to detect, segment, caption, and pose-estimate anything
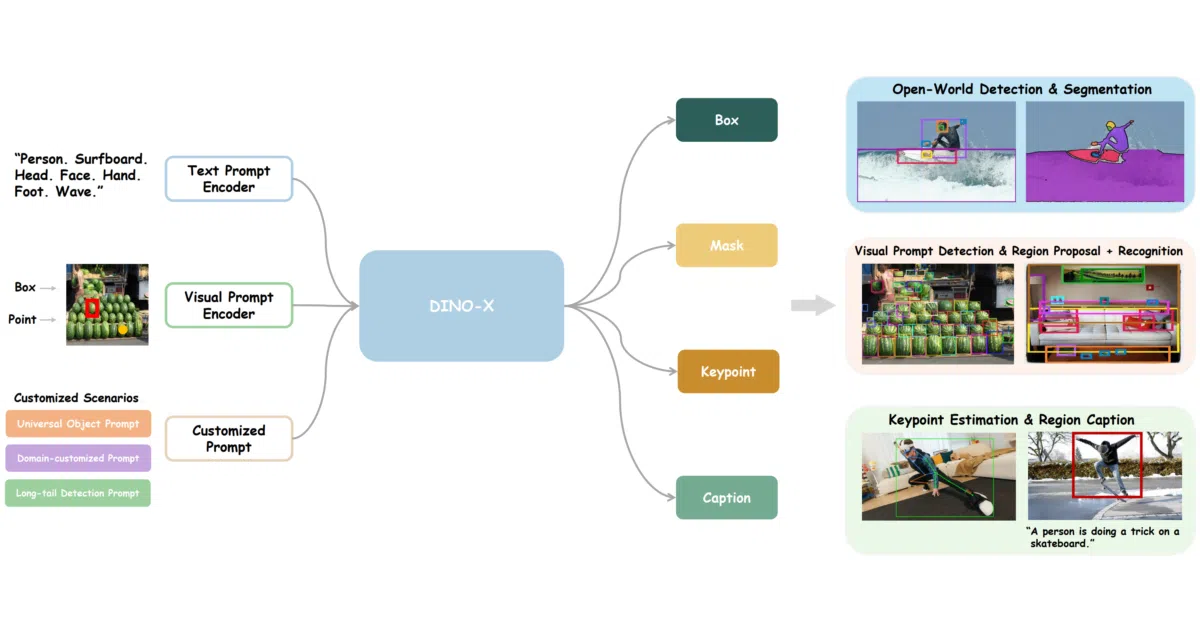
This repo is the official client and demo collection for DINO-X, a hosted unified vision model that handles open-world detection, segmentation, and region captioning from text or visual prompts.
Not currently ranked — collecting fresh signals.
star history
What it does DINO-X-API provides example code and client wrappers for calling DINO-X Pro, a cloud-hosted vision model pitched as a general-purpose object-centric brain. It handles open-set detection, instance segmentation, pose estimation, visual-prompt counting, and region captioning from text, visual, or customized prompts. Because the model itself lives on DeepDataSpace servers, this repository is essentially the SDK and demo gallery.
The interesting bit The model posts benchmark-leading zero-shot detection numbers—56.0 box AP on COCO and 63.3 AP on LVIS rare classes—while also offering a “Prompt-Free Anything Detection” mode that requires no user prompt at all. That dual personality—specialist on long-tail objects, generalist on demand—is unusual in the detection space.
Key highlights
- Claims SOTA zero-shot detection on COCO and LVIS, with large margins on rare/long-tail classes.
- Accepts text, visual, or customized prompts and outputs boxes, masks, keypoints, or captions.
- Supports a prompt-free mode for detection and segmentation without explicit prompting.
- Exposes an MCP server for integration with Cursor, Claude, and other conversational AI tools.
- Recently standardized mask encoding to pycocotools-aligned RLE format (July 2025).
Caveats
- This repository is client code and examples; the actual model weights are hosted remotely on DeepDataSpace and require API tokens.
- The built-in mask head trails Grounded SAM 2 on COCO/LVIS mask AP (37.9 vs. 44.7), though the authors note DINO-X + SAM-Huge narrows the gap.
- The README explicitly states segmentation performance still needs work compared to dedicated SAM pipelines.
Verdict Worth evaluating if you want a single cloud API for eclectic vision tasks—especially long-tail detection—without self-hosting a stack of specialized models. Skip it if you need on-premise inference or best-in-class segmentation out of the box.
Frequently asked
- What is IDEA-Research/DINO-X-API?
- This repo is the official client and demo collection for DINO-X, a hosted unified vision model that handles open-world detection, segmentation, and region captioning from text or visual prompts.
- Is DINO-X-API open source?
- Yes — IDEA-Research/DINO-X-API is open source, released under the Apache-2.0 license.
- What language is DINO-X-API written in?
- IDEA-Research/DINO-X-API is primarily written in Python.
- How popular is DINO-X-API?
- IDEA-Research/DINO-X-API has 1.4k stars on GitHub.
- Where can I find DINO-X-API?
- IDEA-Research/DINO-X-API is on GitHub at https://github.com/IDEA-Research/DINO-X-API.