HKUDS/LightRAG
RAG that draws a map while it reads
It exists because pure vector search often misses the big picture, so LightRAG auto-maps entities and relationships into a knowledge graph for richer retrieval.
Velocity · 7d
+53
★ / day
Trend
↗accelerating
star history
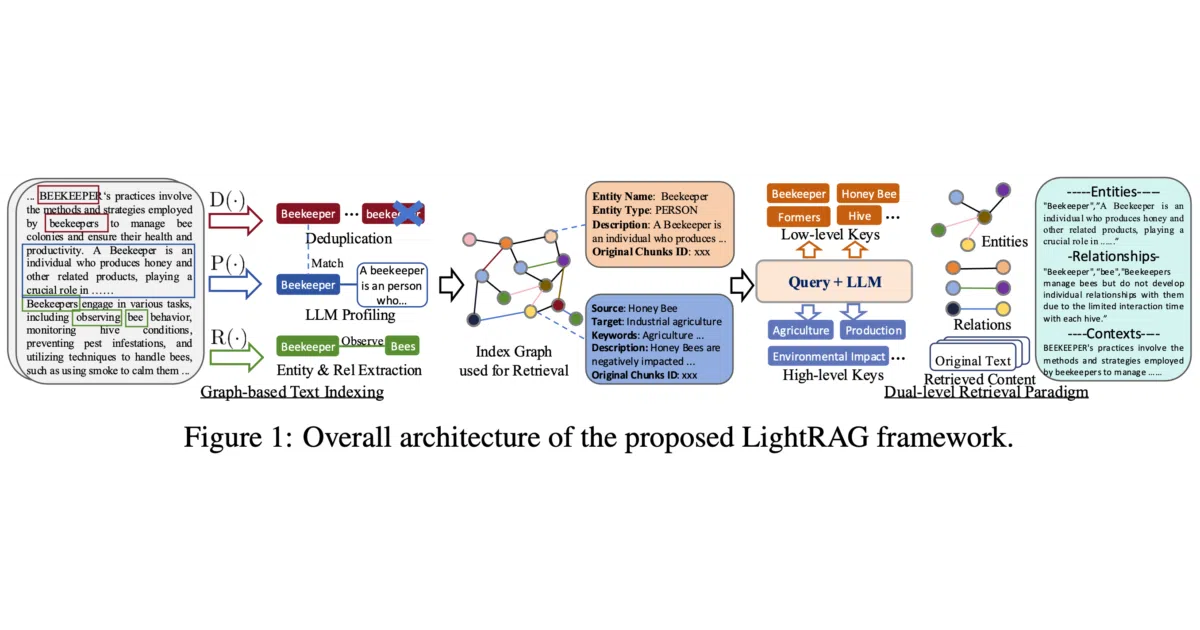
What it does LightRAG ingests documents, extracts entities and relationships, and builds a knowledge graph that it queries alongside traditional vector retrieval. The system answers questions using a dual-level approach: low-level vector matching plus high-level graph traversal. It is packaged as a Python library with an optional server, WebUI, and Ollama-compatible API.
The interesting bit Originally an EMNLP 2025 paper selling “simple and fast” graph RAG, the project has since accumulated an almost comically broad feature set—multimodal parsing via MinerU and Docling, role-specific LLM configs, and a buffet of storage backends including Neo4j, PostgreSQL, MongoDB, and OpenSearch.
Key highlights
- Dual-level retrieval combines vector search with knowledge-graph traversal for context generation
- Four chunking strategies (
Fix,Recursive,Vector,Paragraph) and four independent LLM roles (EXTRACT,QUERY,KEYWORDS,VLM) - Pluggable storage backends: Neo4j, PostgreSQL, MongoDB, OpenSearch, or local JSON/vector stores
- Ships with a WebUI, Docker Compose setup, offline deployment mode, and an Ollama-compatible API endpoint
- Multimodal ingestion through integrated RAG-Anything support for PDFs, images, tables, and equations
Caveats
- The README trumpets “simple and fast” but offers no comparative benchmarks against baseline RAG or GraphRAG
- The feature surface has expanded well beyond the original lightweight algorithm, so “simple” may depend on how many backends you deploy
Verdict A solid choice if you want graph-enhanced retrieval without buying an enterprise knowledge-graph platform, though the growing complexity means it is now closer to a RAG operating system than a drop-in library.
Frequently asked
- What is HKUDS/LightRAG?
- It exists because pure vector search often misses the big picture, so LightRAG auto-maps entities and relationships into a knowledge graph for richer retrieval.
- Is LightRAG open source?
- Yes — HKUDS/LightRAG is open source, released under the MIT license.
- What language is LightRAG written in?
- HKUDS/LightRAG is primarily written in Python.
- How popular is LightRAG?
- HKUDS/LightRAG has 38k stars on GitHub and is currently accelerating.
- Where can I find LightRAG?
- HKUDS/LightRAG is on GitHub at https://github.com/HKUDS/LightRAG.