FunAudioLLM/SenseVoice
A faster Whisper that also reads the room
SenseVoice does speech recognition, emotion detection, and audio event tagging in one non-autoregressive pass—because transcription alone is half the story.
Velocity · 7d
+8.3
★ / day
Trend
↘cooling
star history
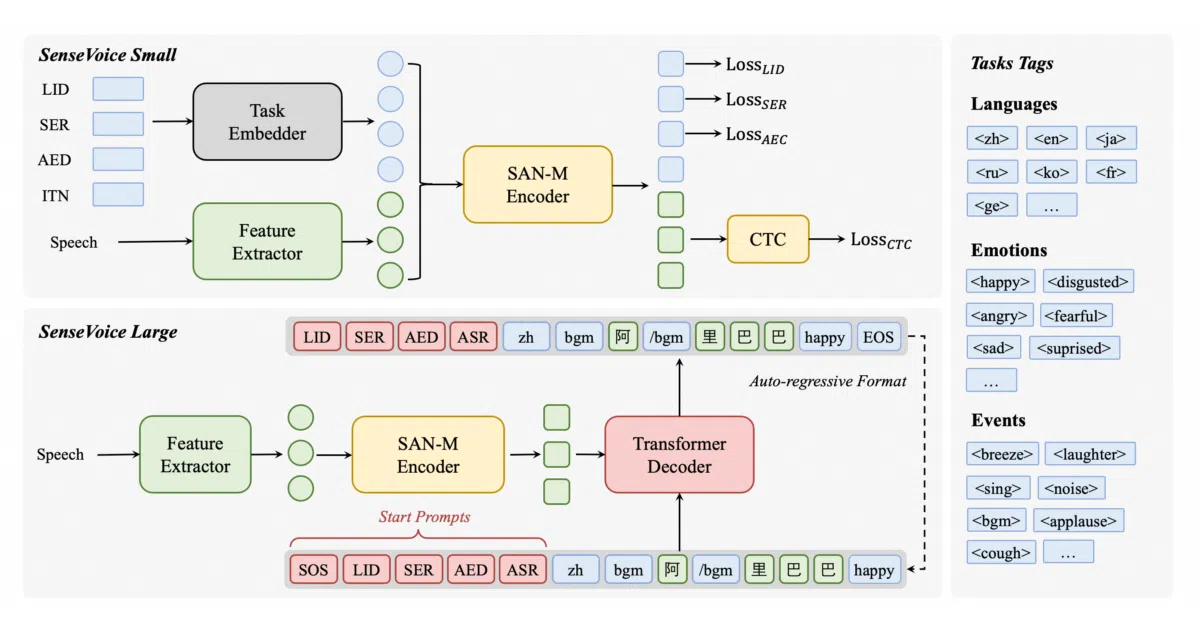
What it does SenseVoice is a speech foundation model that transcribes audio in 50+ languages, identifies the speaker’s emotional state, and detects audio events like applause, laughter, coughing, or background music. It also handles language identification, speaker diarization (via plug-in models), and timestamp generation. The project is essentially a model release and inference wrapper built on the FunASR toolkit.
The interesting bit The Small variant is non-autoregressive, which is where the speed comes from: 70ms to process 10 seconds of audio, or 15× faster than Whisper-Large per the project’s benchmarks. The model was trained on 400,000+ hours of data and claims to outperform Whisper on Chinese and Cantonese recognition specifically. The emotion recognition and audio event detection are unusual bonuses for a general ASR model—though the README concedes its event detection still trails specialized models on non-speech sound classification.
Key highlights
- Single model handles ASR, emotion recognition, language ID, and audio event detection
- Non-autoregressive Small model: 70ms inference for 10s audio, 15× faster than Whisper-Large
- Supports 50+ languages; claims superior Chinese/Cantonese accuracy vs. Whisper
- Speaker diarization available by chaining VAD + CAM++ speaker model + punctuation model
- ONNX and LibTorch export supported; service deployment pipeline with multi-client support (Python, C++, Java, C#, HTML)
- Fine-tuning scripts provided for domain adaptation
Caveats
- Speaker diarization requires installing FunASR from source, not the stable release
- Audio event detection works but lags behind dedicated models like BEATS or PANN on non-speech sounds
- Benchmarks are self-reported; independent verification unclear
Verdict Worth evaluating if you need low-latency multilingual transcription with emotion or acoustic context baked in—especially for Chinese-language applications. Skip if you need best-in-class general audio event detection or prefer a more mature, independently benchmarked ecosystem.
Frequently asked
- What is FunAudioLLM/SenseVoice?
- SenseVoice does speech recognition, emotion detection, and audio event tagging in one non-autoregressive pass—because transcription alone is half the story.
- Is SenseVoice open source?
- Yes — FunAudioLLM/SenseVoice is open source, released under the MIT license.
- What language is SenseVoice written in?
- FunAudioLLM/SenseVoice is primarily written in C.
- How popular is SenseVoice?
- FunAudioLLM/SenseVoice has 8.9k stars on GitHub and is currently cooling off.
- Where can I find SenseVoice?
- FunAudioLLM/SenseVoice is on GitHub at https://github.com/FunAudioLLM/SenseVoice.