FreedomIntelligence/HuatuoGPT-o1
A medical LLM that checks its own homework
It trains medical LLMs to reason aloud, then grades their thinking with a specialized verifier instead of just rewarding fluent answers.
Not currently ranked — collecting fresh signals.
star history
What it does
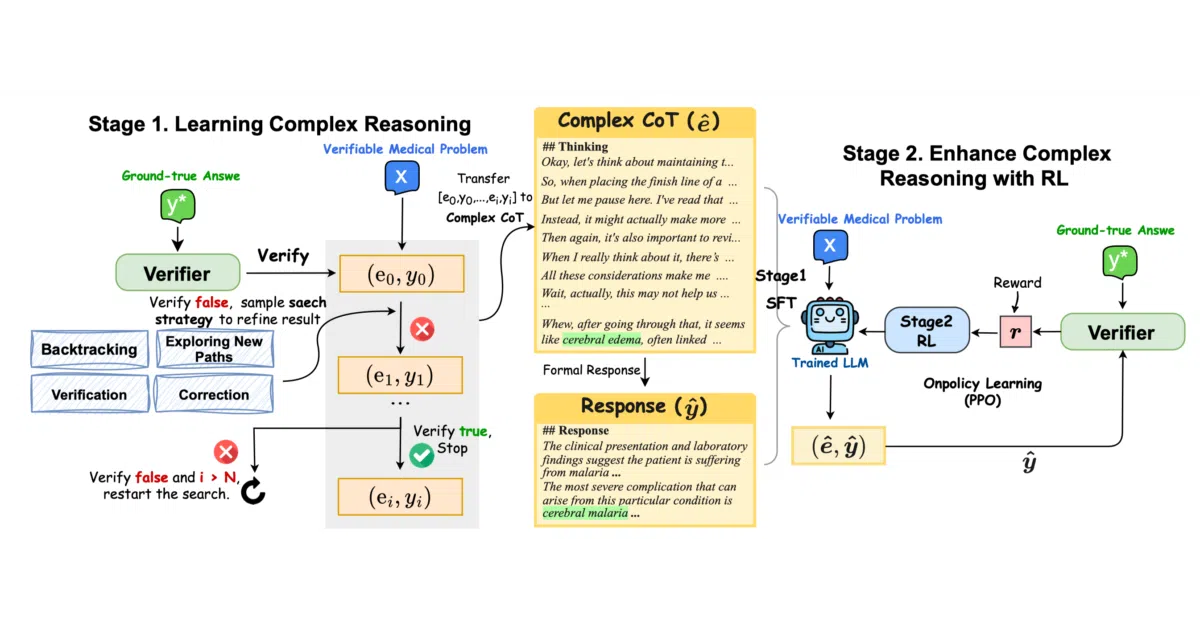
HuatuoGPT-o1 is a family of medical LLMs—built on LLaMA 3.1 and Qwen2.5 backbones—that generate explicit reasoning chains before answering. It is trained to identify errors, explore alternatives, and refine its conclusions using verifiable medical problems drawn from challenging clinical exams.
The interesting bit
Instead of relying on imitation learning alone, the project uses a dedicated 3B medical verifier as a reward model. This verifier guides the search for correct reasoning trajectories during supervised fine-tuning and provides reward signals for PPO-based reinforcement learning, scoring the logic rather than the prose.
Key highlights
- Models range from 7B to 72B parameters, with Qwen-based variants supporting both English and Chinese.
- Outputs are structured into explicit
## Thinkingand## Final Responsesections, making the reasoning inspectable. - The training pipeline, data construction scripts, and a medical verifier model are all openly released.
- Training data includes complex chains of thought generated from verifiable open-ended medical problems with ground-truth answers.
Caveats
- Data construction and reasoning-path search scripts depend on GPT-4o API access, which may limit reproducibility.
- The default evaluation setup uses free-response prompts with post-hoc extraction rather than strict constrained generation.
Verdict
Worth exploring if you are building medical QA systems or studying verifiable reasoning in narrow domains. Skip it if you need a turnkey clinical product—this is a research release with open training pipelines, not a finished diagnostic tool.
Frequently asked
- What is FreedomIntelligence/HuatuoGPT-o1?
- It trains medical LLMs to reason aloud, then grades their thinking with a specialized verifier instead of just rewarding fluent answers.
- Is HuatuoGPT-o1 open source?
- Yes — FreedomIntelligence/HuatuoGPT-o1 is an open-source project tracked on heatdrop.
- What language is HuatuoGPT-o1 written in?
- FreedomIntelligence/HuatuoGPT-o1 is primarily written in Python.
- How popular is HuatuoGPT-o1?
- FreedomIntelligence/HuatuoGPT-o1 has 1.3k stars on GitHub.
- Where can I find HuatuoGPT-o1?
- FreedomIntelligence/HuatuoGPT-o1 is on GitHub at https://github.com/FreedomIntelligence/HuatuoGPT-o1.