Doragd/Chinese-Chatbot-PyTorch-Implementation
A student chatbot that admits its flaws
Coursework project documenting the painful gap between reading PyTorch tutorials and actually training a Chinese seq2seq model that converges.
Not currently ranked — collecting fresh signals.
star history
What it does
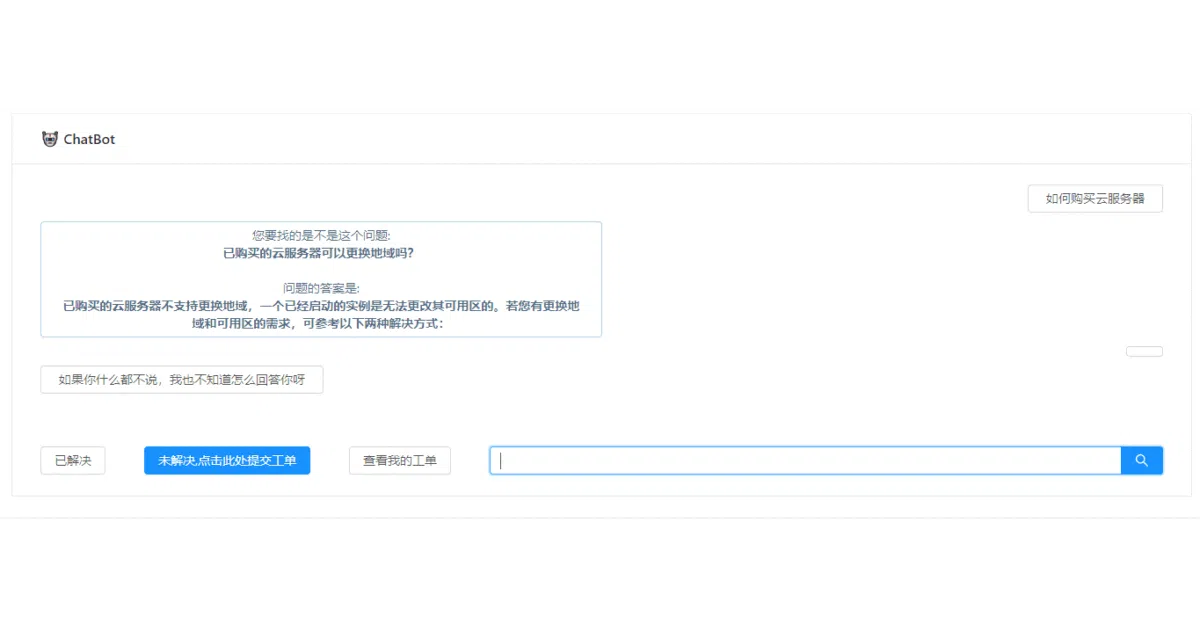
A Chinese chatbot built on the qingyun corpus (100k casual dialogue pairs) using a standard seq2seq architecture: bidirectional GRU encoder, unidirectional GRU decoder, global dot-product attention. It can run in two modes—retrieve from a small hand-curated knowledge base first (100 Tencent Cloud Q&A pairs), or fall back to neural generation.
The interesting bit
The README’s “pitfall journal” is the real artifact. The author meticulously records every humbling discovery: model.to(device) doesn’t move member tensors defined in forward, batch size mysteriously affects convergence, and torch.long is not “high-precision float.” It’s a rare public record of the debugging density between tutorial comprehension and working code.
Key highlights
- Pre-trained checkpoint included (
chatbot_0509_1437); skip preprocessing if desired - Greedy search decoder implemented; beam search is stubbed as “to do”
- Evaluation is qualitative only—“quantitative evaluation not yet written, should use perplexity”
- Code follows class-based structure refactored from the official PyTorch chatbot tutorial
- Chinese word segmentation via jieba; author notes quality issues from missing stopword filtering
Caveats
- Author explicitly states the model “doesn’t work very well” and cites segmentation quality as a key bottleneck
- Beam search unfinished; no quantitative metrics implemented
- Knowledge base is tiny (100 entries) and domain-specific to Tencent Cloud services
Verdict
Worth browsing for the honest debugging notes if you’re a student bridging PyTorch tutorials to your first real NLP project. Skip if you need a production Chinese dialogue system or reproducible benchmarks.
Frequently asked
- What is Doragd/Chinese-Chatbot-PyTorch-Implementation?
- Coursework project documenting the painful gap between reading PyTorch tutorials and actually training a Chinese seq2seq model that converges.
- Is Chinese-Chatbot-PyTorch-Implementation open source?
- Yes — Doragd/Chinese-Chatbot-PyTorch-Implementation is open source, released under the Apache-2.0 license.
- What language is Chinese-Chatbot-PyTorch-Implementation written in?
- Doragd/Chinese-Chatbot-PyTorch-Implementation is primarily written in Python.
- How popular is Chinese-Chatbot-PyTorch-Implementation?
- Doragd/Chinese-Chatbot-PyTorch-Implementation has 916 stars on GitHub.
- Where can I find Chinese-Chatbot-PyTorch-Implementation?
- Doragd/Chinese-Chatbot-PyTorch-Implementation is on GitHub at https://github.com/Doragd/Chinese-Chatbot-PyTorch-Implementation.