DAMO-NLP-SG/VideoLLaMA3
Video leaderboards' current 7B champion is smaller than you think
VideoLLaMA3 is a family of 2B and 7B vision-language models built on Qwen2.5 that reads charts, documents, and long videos in addition to plain images.
Not currently ranked — collecting fresh signals.
star history
What it does VideoLLaMA3 is a collection of multimodal models—2B and 7B parameter variants built on Qwen2.5—that accept images or video clips and answer questions about them. You feed it a video path with a target frame rate and maximum frame count, or pass in images and text prompts, and it generates responses via standard Transformers inference. The project also provides image-only checkpoints and a separately downloadable tuned SigLIP vision encoder.
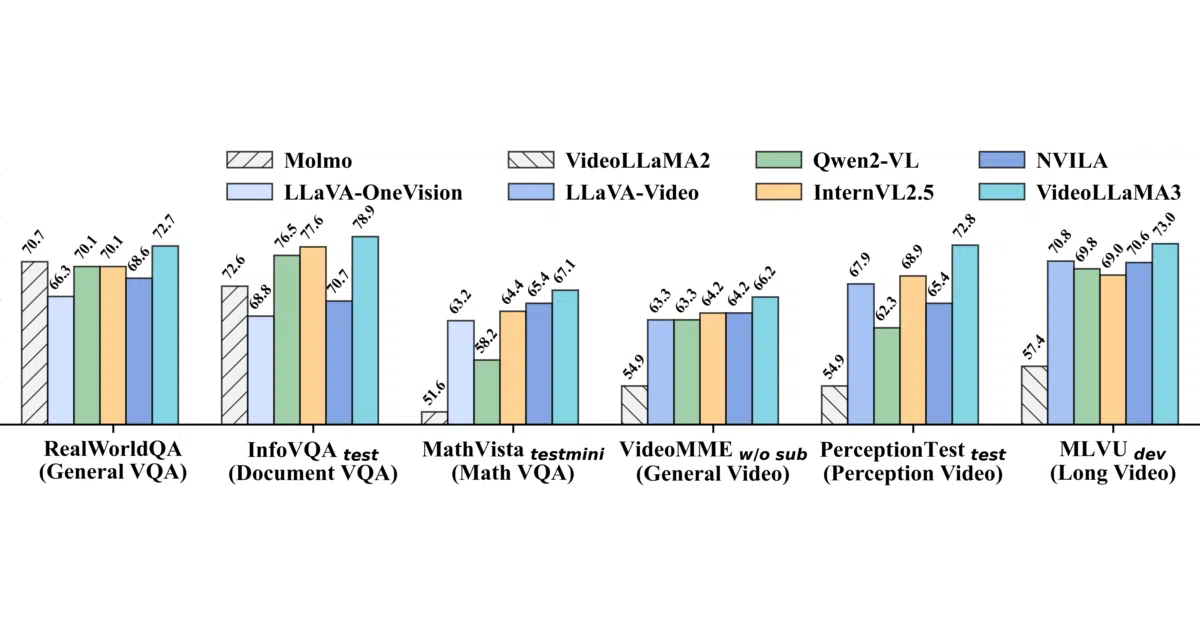
The interesting bit As of late January 2025, the 7B model ranks first among 7B-sized entries on both the LVBench and VideoMME leaderboards, which test long-video and multi-modal reasoning. The team also released the synthetic re-captioning dataset VL3-Syn7M used to train it, so you can inspect the training diet rather than guessing.
Key highlights
- 2B and 7B parameter models with dedicated image-only variants
- #1 ranked 7B model on LVBench and VideoMME leaderboards (as of Jan 2025)
- Handles fine-grained tasks: visual referring, grounding, chart analysis, table understanding, and document recognition
- Tuned vision encoder (SigLIP-NaViT) released separately for reuse in other pipelines
- Runs via Hugging Face Transformers with Flash Attention 2 and
bfloat16
Caveats
- Requires
trust_remote_code=Trueand a fragile dependency stack (PyTorch 2.4.0, flash-attn 2.7.3 for CUDA 11.8) - README is strong on benchmark screenshots but sparse on architecture and training details
- Leaderboard claims are bold for a relatively new repo; verify against your own video tasks
Verdict Try it if you need a compact, video-capable VLM that also handles documents and charts. Look elsewhere if you want a fully transparent training recipe or an architecture without custom remote code.
Frequently asked
- What is DAMO-NLP-SG/VideoLLaMA3?
- VideoLLaMA3 is a family of 2B and 7B vision-language models built on Qwen2.5 that reads charts, documents, and long videos in addition to plain images.
- Is VideoLLaMA3 open source?
- Yes — DAMO-NLP-SG/VideoLLaMA3 is open source, released under the Apache-2.0 license.
- What language is VideoLLaMA3 written in?
- DAMO-NLP-SG/VideoLLaMA3 is primarily written in Jupyter Notebook.
- How popular is VideoLLaMA3?
- DAMO-NLP-SG/VideoLLaMA3 has 1.2k stars on GitHub.
- Where can I find VideoLLaMA3?
- DAMO-NLP-SG/VideoLLaMA3 is on GitHub at https://github.com/DAMO-NLP-SG/VideoLLaMA3.