ConardLi/easy-dataset
The Point-and-Click Dataset Factory for LLMs
It wraps the messy pipeline of parsing, chunking, and synthetic QA generation into a single visual tool for LLM fine-tuning and evaluation.
Velocity · 7d
+4.1
★ / day
Trend
↘cooling
star history
What it does
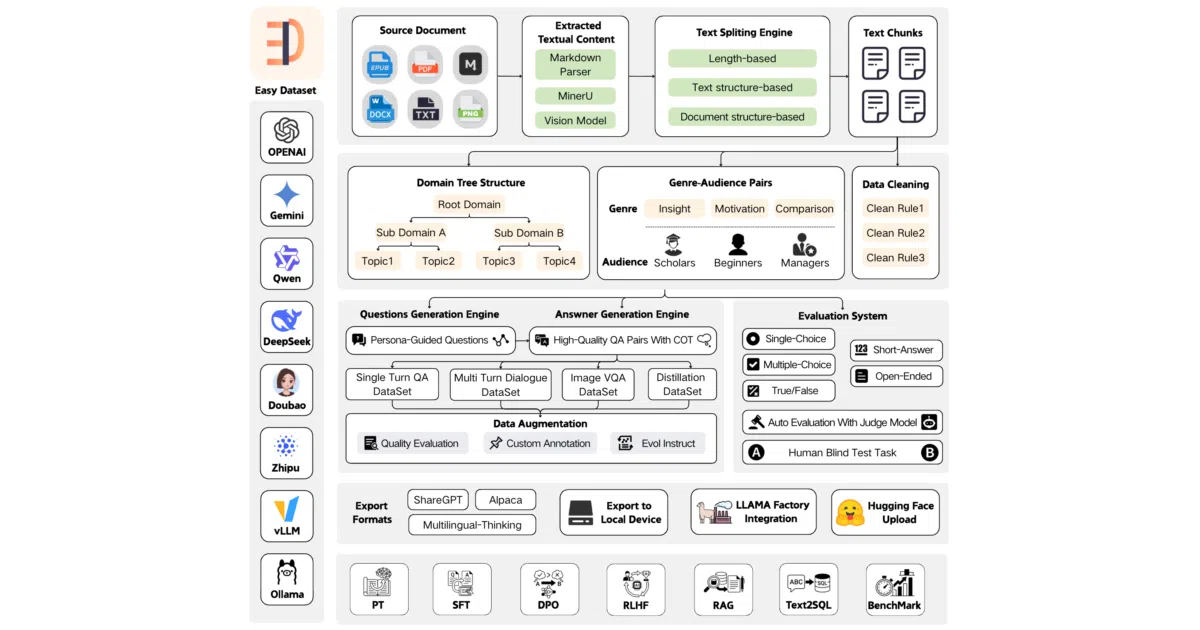
Easy Dataset is a desktop and web application that ingests documents—PDF, Word, Markdown, EPUB—and converts them into structured datasets for fine-tuning or RAG. It chunks text using several strategies, generates synthetic questions and chain-of-thought answers via LLM APIs, cleans the results, and exports to formats like Alpaca and ShareGPT. It also builds evaluation sets and runs automated model comparisons.
The interesting bit
Instead of just dumping JSON, it tries to own the whole lifecycle: a built-in judge model scores outputs automatically, a double-blind arena lets humans compare answers, and a dashboard tracks token burn and API calls. It even spits out LLaMA Factory configs and uploads straight to Hugging Face, turning a messy pipeline into a point-and-click workshop.
Key highlights
- Ingests PDF, DOCX, TXT, EPUB, and images, using vision models such as Gemini and Claude for PDF parsing and visual QA.
- Splits text by Markdown structure, recursive separators, fixed length, or code-aware chunking, with a visual segmentation editor.
- Produces single-turn QA, multi-turn dialogue, and image-based QA datasets, or generates questions directly from domain topics without source documents.
- Evaluates models with true/false, multiple-choice, short-answer, and open-ended test sets, plus an automated judge and a human blind-test arena.
- Exports to Alpaca, ShareGPT, and Multilingual-Thinking formats; one-click LLaMA Factory configuration; direct Hugging Face Hub upload.
- Works with any OpenAI-format API, including local models via Ollama, and supports providers like OpenRouter, Zhipu AI, and MiniMax.
Verdict
Grab it if you need to bootstrap domain-specific training data from a pile of documents and prefer a GUI to a stack of Jupyter notebooks. Pass if your data is already structured and you just need a format converter.
Frequently asked
- What is ConardLi/easy-dataset?
- It wraps the messy pipeline of parsing, chunking, and synthetic QA generation into a single visual tool for LLM fine-tuning and evaluation.
- Is easy-dataset open source?
- Yes — ConardLi/easy-dataset is an open-source project tracked on heatdrop.
- What language is easy-dataset written in?
- ConardLi/easy-dataset is primarily written in JavaScript.
- How popular is easy-dataset?
- ConardLi/easy-dataset has 14.7k stars on GitHub and is currently cooling off.
- Where can I find easy-dataset?
- ConardLi/easy-dataset is on GitHub at https://github.com/ConardLi/easy-dataset.