CompVis/taming-transformers
High-res images by letting transformers arrange CNN codebooks
It makes high-resolution image generation tractable for transformers by handing them a discrete codebook of visual parts learned by a CNN.
Not currently ranked — collecting fresh signals.
star history
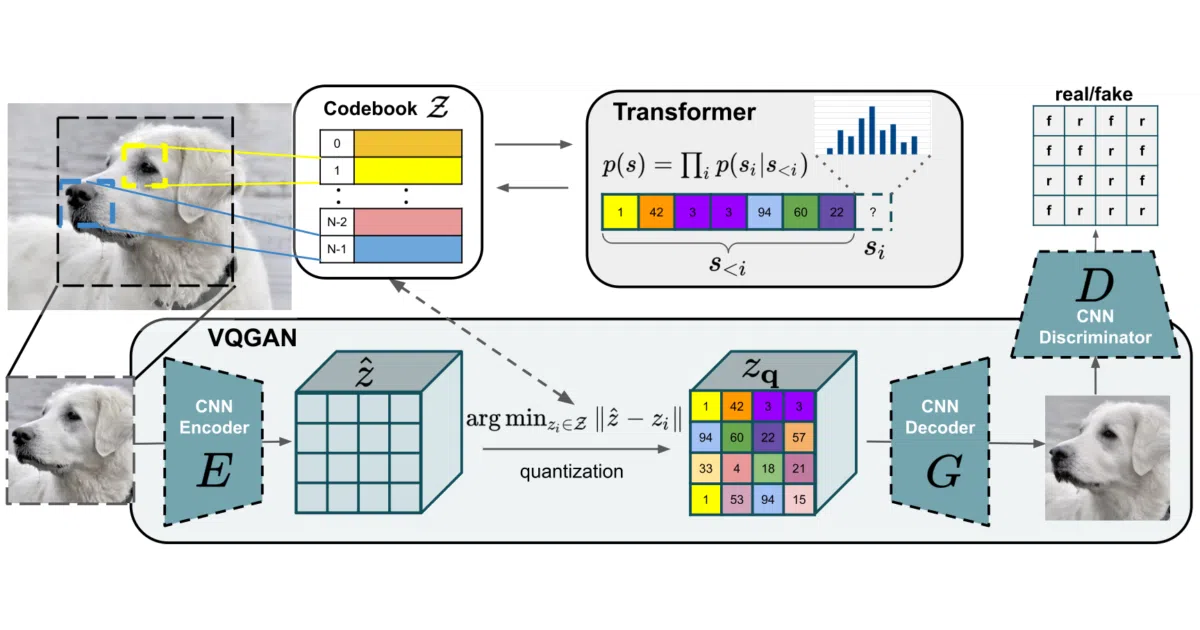
What it does The project implements a two-stage generator: a convolutional VQGAN learns a discrete codebook of image patches, and an autoregressive transformer learns to compose those patches into full images. It supports class-conditional and unconditional synthesis across ImageNet, faces, landscapes, and scene datasets like COCO and ADE20K.
The interesting bit The trick is separation of concerns. The CNN handles local spatial structure and compresses the image into context-rich tokens, while the transformer handles long-range dependencies by predicting token sequences. It is essentially a compression algorithm followed by a very expensive autocomplete.
Key highlights
- Pretrained models include a 1.4B-parameter ImageNet transformer that the authors report outperforms BigGAN in FID among autoregressive approaches.
- Supports diverse conditioning: segmentation maps, depth maps, bounding boxes, and class labels.
- Ships with reconstruction benchmarks comparing its VQGAN against OpenAI’s DALL-E dVAE in an included Colab notebook.
- A quantizer bugfix is present but disabled by default for backward compatibility; you must explicitly set
legacy=Falseto enable it.
Caveats
- The README functions largely as a model zoo and launcher manual; architectural depth is limited to the abstract-level summary.
- Newer VQGAN variants and checkpoints have migrated to the successor Latent Diffusion Models repository.
- The quantizer ships with the pre-bugfix behavior enabled by default, which is a footgun for reproducibility.
Verdict A solid reference for researchers building on discrete token-based generation or training custom VQGANs; less useful if you are looking for a turnkey, modern text-to-image interface.
Frequently asked
- What is CompVis/taming-transformers?
- It makes high-resolution image generation tractable for transformers by handing them a discrete codebook of visual parts learned by a CNN.
- Is taming-transformers open source?
- Yes — CompVis/taming-transformers is open source, released under the MIT license.
- What language is taming-transformers written in?
- CompVis/taming-transformers is primarily written in Jupyter Notebook.
- How popular is taming-transformers?
- CompVis/taming-transformers has 6.5k stars on GitHub.
- Where can I find taming-transformers?
- CompVis/taming-transformers is on GitHub at https://github.com/CompVis/taming-transformers.