CQFIO/PhotographicImageSynthesis
Paint-by-numbers for neural networks: semantic maps to photorealism
A 2017 ICCV paper that turns crude color-coded scene layouts into convincing photographs through a cascade of ever-finer refinement networks.
Not currently ranked — collecting fresh signals.
star history
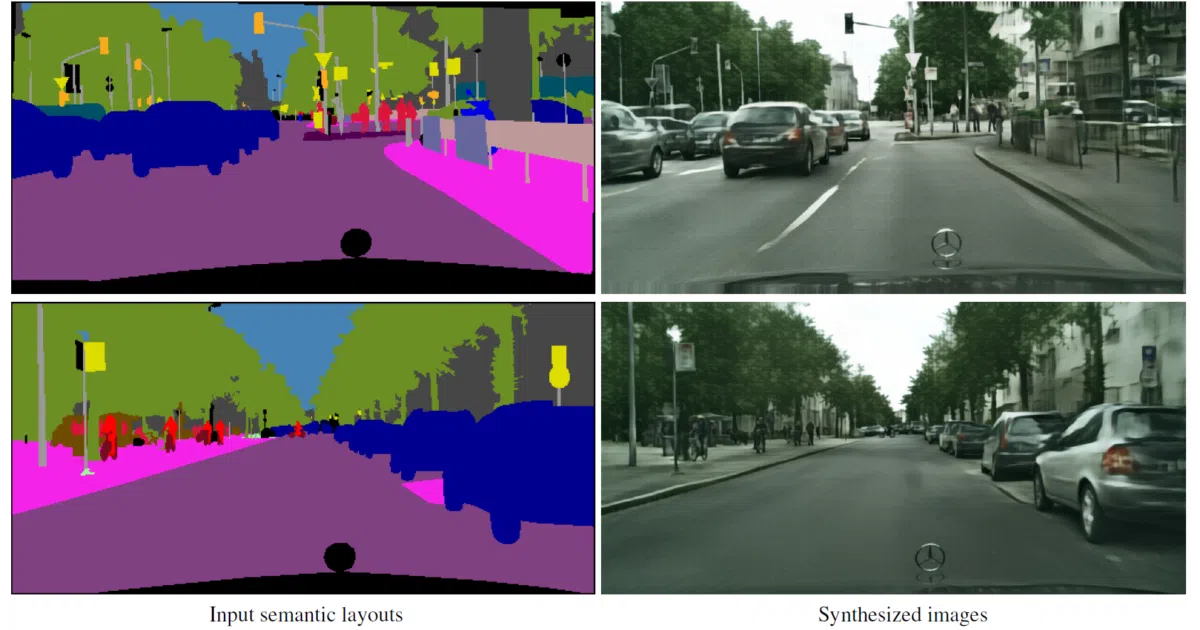
What it does Feed it a semantic layout — basically a paint-by-numbers map where each color means “sky” or “road” or “car” — and it synthesizes a photographic image at up to 1024p. The TensorFlow implementation includes pretrained models and demo scripts for three resolutions, plus training code if you want to roll your own.
The interesting bit The architecture works like a printmaker’s proofing process: train at low resolution (256p), then fine-tune upward through 512p to 1024p. Each stage refines what the previous one sketched, rather than trying to hallucinate full detail in one shot. It’s an older approach now, but the progressive refinement idea still shows up in modern diffusion pipelines.
Key highlights
- Pretrained models available via
python download_models.py; demos run at 512p or 1024p (the latter needs a beefy GPU) - Training follows a three-stage resolution ladder: 256p → 512p → 1024p, each fine-tuned from the last
- Includes Mechanical Turk scripts for whatever human evaluation they ran
- MIT licensed; tested on Ubuntu + Titan X Pascal with CUDA 8.0+
- CPU mode “should work with minor changes” — the README’s words, not a guarantee
Caveats
- Stuck on TensorFlow 1.x era; don’t expect clean runs on modern stacks without archaeology
- GTA dataset code/models still on the todo list, and the NYU pretrained model requires emailing the author directly
- No mention of training data sources, dataset sizes, or hardware/time requirements for training from scratch
Verdict Worth a look if you’re studying the evolution of image synthesis or need a concrete, well-cited baseline to beat. Skip it if you want production-ready code; this is researchware from the GAN era, complete with the usual rough edges.
Frequently asked
- What is CQFIO/PhotographicImageSynthesis?
- A 2017 ICCV paper that turns crude color-coded scene layouts into convincing photographs through a cascade of ever-finer refinement networks.
- Is PhotographicImageSynthesis open source?
- Yes — CQFIO/PhotographicImageSynthesis is an open-source project tracked on heatdrop.
- What language is PhotographicImageSynthesis written in?
- CQFIO/PhotographicImageSynthesis is primarily written in Python.
- How popular is PhotographicImageSynthesis?
- CQFIO/PhotographicImageSynthesis has 1.2k stars on GitHub.
- Where can I find PhotographicImageSynthesis?
- CQFIO/PhotographicImageSynthesis is on GitHub at https://github.com/CQFIO/PhotographicImageSynthesis.