Azzedde/paper_to_podcast
Your commute just got a tenure-track co-host
A Python pipeline that turns dry PDFs into three-voice podcast debates, because reading is for people not stuck on the subway.
Not currently ranked — collecting fresh signals.
star history
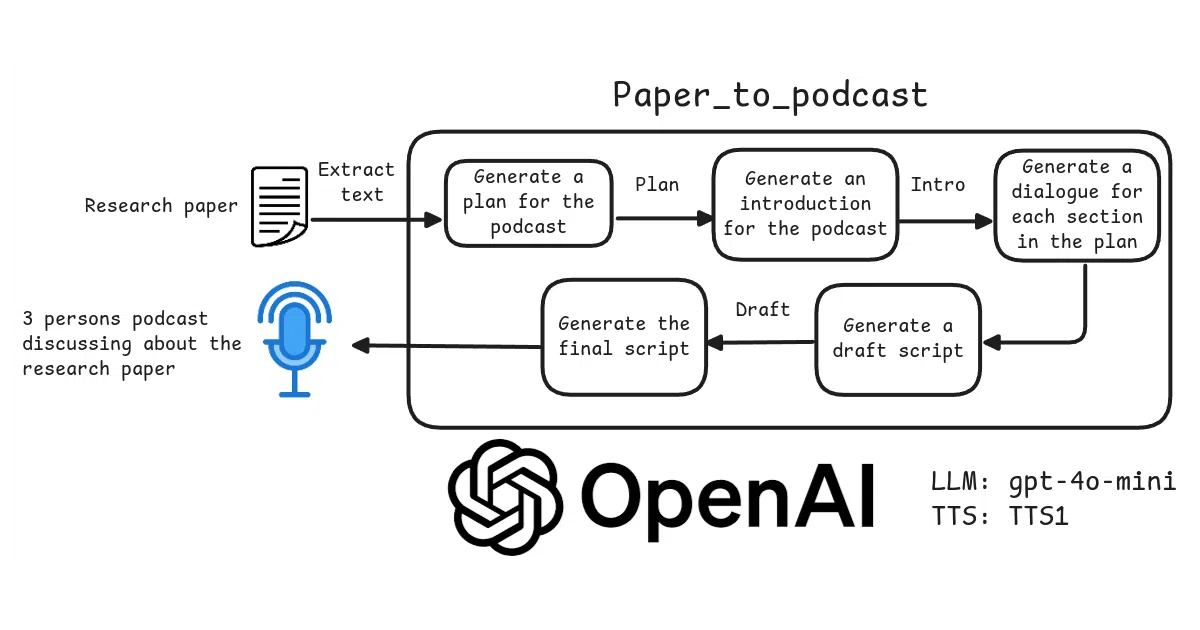
What it does Feed it a research paper PDF and it spits out a ~10-minute audio discussion: a host, a curious learner, and an expert arguing over your commute. The pipeline plans, scripts, and voices the whole thing via OpenAI’s API, then hands you an MP3.
The interesting bit The three-person format isn’t just theater—it’s structural. The “planning chain” maps the paper first, then a retrieval-augmented “discussion chain” keeps the dialogue anchored to actual source content, and an “enhancement chain” scrubs redundancies. It’s basically a tiny assembly line for synthetic Socratic method.
Key highlights
- Three fixed personas (Host / Learner / Expert) with distinct voice roles
- RAG-based discussion generation to limit hallucinations
- OpenAI TTS with realistic voice differentiation per character
- ~$0.16 to convert a 19-page paper into 9 minutes of audio
- Sample outputs live in
./sample_podcasts
Caveats
- Currently OpenAI-only; local LLM/TTS support is on the roadmap but not implemented
- Generation is slow; the README explicitly flags runtime as a known pain point
- Single PDF input, no batch processing or URL fetching mentioned
Verdict Great for researchers who want to audit papers while walking the dog, or educators building accessible content. Skip it if you need real-time generation, open-source stack purity, or anything beyond the hardcoded three-host format.
Frequently asked
- What is Azzedde/paper_to_podcast?
- A Python pipeline that turns dry PDFs into three-voice podcast debates, because reading is for people not stuck on the subway.
- Is paper_to_podcast open source?
- Yes — Azzedde/paper_to_podcast is open source, released under the Apache-2.0 license.
- What language is paper_to_podcast written in?
- Azzedde/paper_to_podcast is primarily written in Python.
- How popular is paper_to_podcast?
- Azzedde/paper_to_podcast has 618 stars on GitHub.
- Where can I find paper_to_podcast?
- Azzedde/paper_to_podcast is on GitHub at https://github.com/Azzedde/paper_to_podcast.