Azure-Samples/chat-with-your-data-solution-accelerator
Azure's RAG starter kit: more knobs than the managed version
A deployable baseline for when Azure's out-of-the-box RAG doesn't fit your business rules.
Not currently ranked — collecting fresh signals.
star history
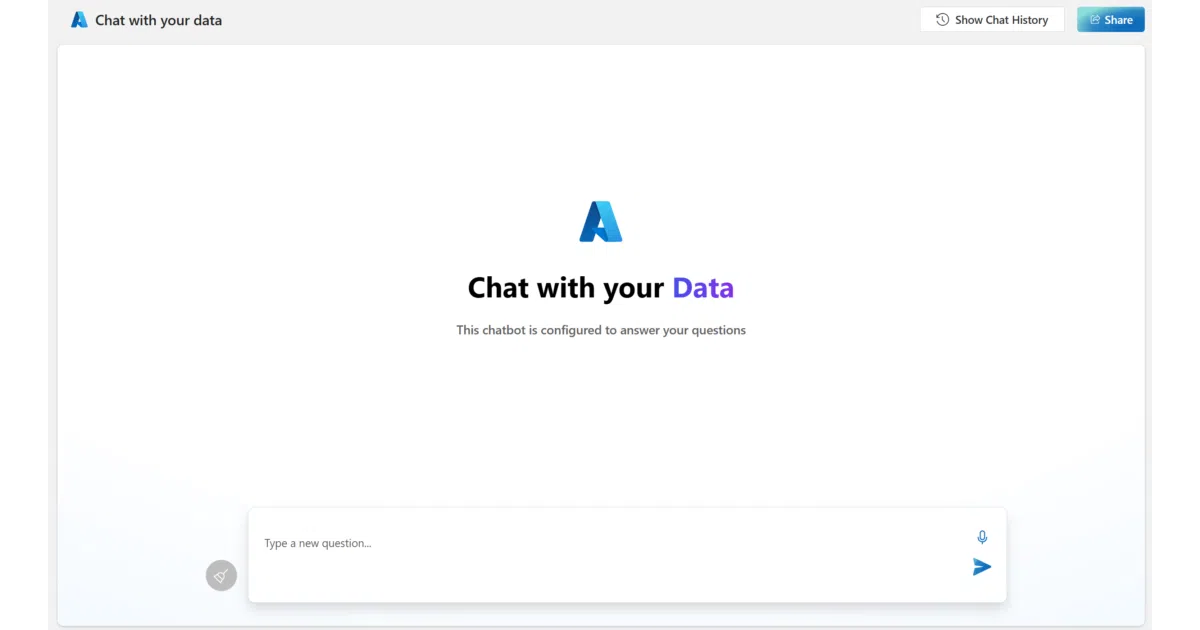
What it does This is Microsoft’s reference implementation of retrieval-augmented generation (RAG) on Azure: upload documents, index them in Azure AI Search, then query via an Azure OpenAI GPT model through a web UI with chat history and speech-to-text. It deploys as a full stack—ingestion pipeline, admin site, and chat frontend—into your own subscription.
The interesting bit The README is unusually honest about its place in the ecosystem. This accelerator exists for the gap between “Azure OpenAI on your data” (managed, limited customization) and building from scratch. It exposes choices the managed service hides: Semantic Kernel vs. LangChain vs. Prompt Flow for orchestration, push vs. pull ingestion, chunk size and overlap strategies, and even PostgreSQL or Cosmos DB for chat persistence.
Key highlights
- Four orchestration options: Semantic Kernel, LangChain, OpenAI Functions, or Prompt Flow
- Ingestion via drag-and-drop, storage pointing, or integrated vectorization (pull model)
- Admin site for runtime prompt tuning, document inspection, and dataset configuration
- Speech-to-text input and source-document citations in the chat window
- Teams extension reuses the same backend for Microsoft Teams integration
- Defaults to PostgreSQL for chat history, with Cosmos DB as an alternative
Caveats
- Explicitly not production-ready without tuning chunk size, overlap, retrieval type, and system prompt for your data
- Single default RAG configuration out of the box; evaluation and experimentation required
- README warns you will need to add your own code to meet business requirements
Verdict Grab this if you’re an Azure shop that needs to customize RAG orchestration or ingestion beyond what the managed service allows, and you have bandwidth to tune and extend. Skip it if Azure OpenAI on your data already meets your needs—you’ll pay complexity for options you won’t use.
Frequently asked
- What is Azure-Samples/chat-with-your-data-solution-accelerator?
- A deployable baseline for when Azure's out-of-the-box RAG doesn't fit your business rules.
- Is chat-with-your-data-solution-accelerator open source?
- Yes — Azure-Samples/chat-with-your-data-solution-accelerator is open source, released under the MIT license.
- What language is chat-with-your-data-solution-accelerator written in?
- Azure-Samples/chat-with-your-data-solution-accelerator is primarily written in Python.
- How popular is chat-with-your-data-solution-accelerator?
- Azure-Samples/chat-with-your-data-solution-accelerator has 1.2k stars on GitHub.
- Where can I find chat-with-your-data-solution-accelerator?
- Azure-Samples/chat-with-your-data-solution-accelerator is on GitHub at https://github.com/Azure-Samples/chat-with-your-data-solution-accelerator.