ArrowLuo/CLIP4Clip
CLIP goes to film school: video retrieval with a frozen ViT
A 2021 study in how far you can stretch OpenAI's image-text model before training a single video-specific weight.
Not currently ranked — collecting fresh signals.
star history
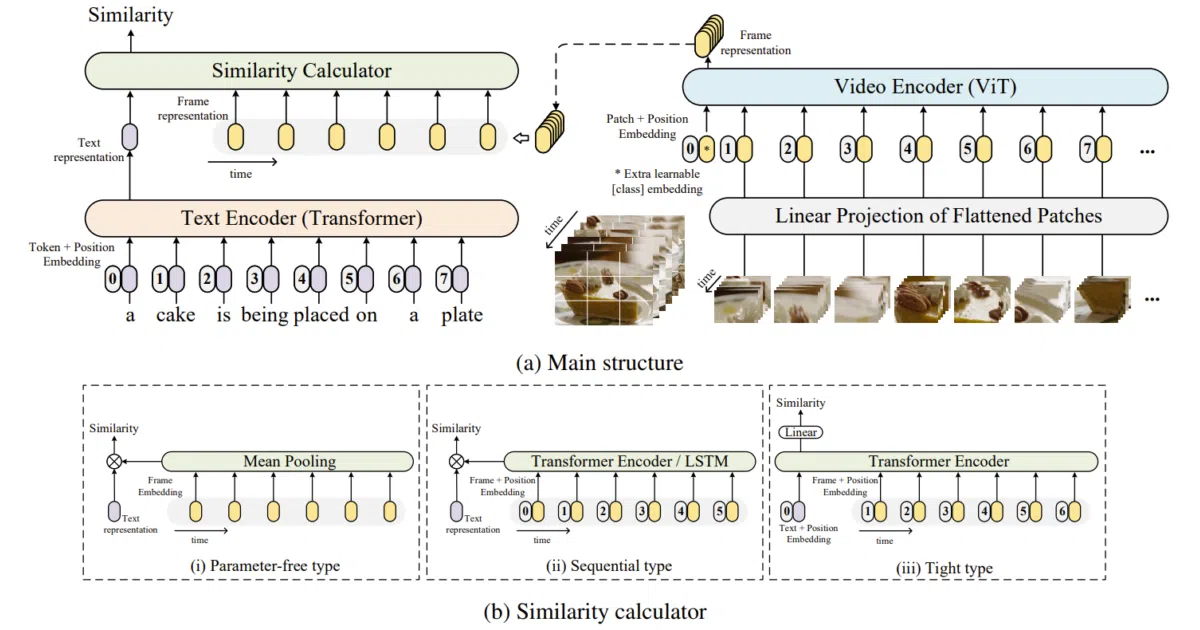
What it does CLIP4Clip adapts OpenAI’s CLIP (ViT-B) to retrieve video clips from text queries. It treats video as a sequence of frames, feeds them through the frozen image encoder, then experiments with four ways to pool or transform those frame embeddings into something comparable to a text embedding. The code covers five standard benchmarks: MSR-VTT, MSVD, LSMDC, ActivityNet, and DiDeMo.
The interesting bit The paper’s real contribution is the ablation, not the architecture. The authors systematically compare a parameter-free mean pool, an LSTM, a Transformer, and a “tight” cross-modal Transformer—asking how much temporal machinery you actually need when the backbone already “understands” so much. Spoiler: the simple mean pool (meanP) is the default, and the fancier options are there for you to test.
Key highlights
- Built entirely on frozen CLIP ViT-B/32 or ViT-B/16 weights; no video pretraining required
- Four similarity heads:
meanP,seqLSTM,seqTransf,tightTransf - Optional 2D or 3D linear patch projection for frame tokens
- Distributed training scripts provided for all five datasets, with per-dataset hyperparameters already tuned
- Includes a preprocessing script to compress videos to 3 fps / 224 px for faster loading
Caveats
- The README is essentially a collection of shell scripts; you’ll need to read the paper to understand what
linear_patchandsim_headeractually do - LSMDC requires MPII permission; ActivityNet and DiDeMo expect 8 GPUs or multi-node setup
- Last meaningful update was July 2021 (ViT-B/16 support); PyTorch 1.7.1 and CUDA 11.0 in the requirements feel increasingly archaeological
Verdict Grab this if you’re benchmarking video-text retrieval or probing how far CLIP’s zero-shot transfer really goes. Skip it if you want a modern, maintained framework—this is a research artifact, not a product.
Frequently asked
- What is ArrowLuo/CLIP4Clip?
- A 2021 study in how far you can stretch OpenAI's image-text model before training a single video-specific weight.
- Is CLIP4Clip open source?
- Yes — ArrowLuo/CLIP4Clip is open source, released under the MIT license.
- What language is CLIP4Clip written in?
- ArrowLuo/CLIP4Clip is primarily written in Python.
- How popular is CLIP4Clip?
- ArrowLuo/CLIP4Clip has 1k stars on GitHub.
- Where can I find CLIP4Clip?
- ArrowLuo/CLIP4Clip is on GitHub at https://github.com/ArrowLuo/CLIP4Clip.