AlignmentResearch/tuned-lens
X-ray specs for transformers: peeking inside layer by layer
A tuned lens lets you skip ahead in a transformer and see what it's thinking before it's done thinking.
Not currently ranked — collecting fresh signals.
star history
What it does
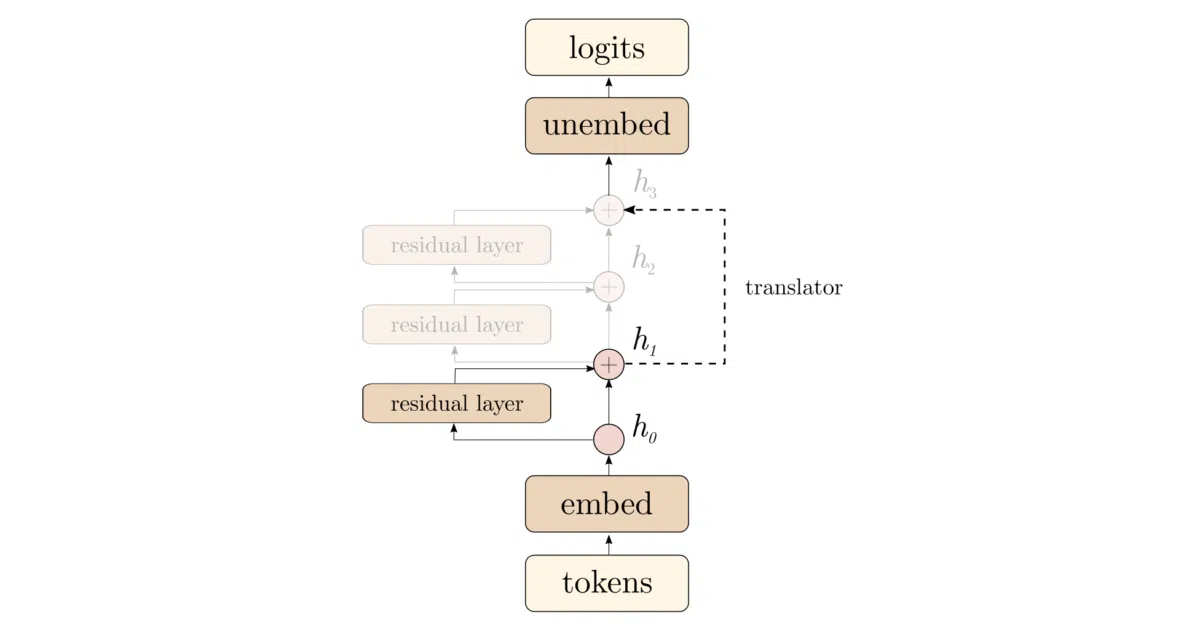
Tuned Lens trains small affine “translators” that sit between intermediate layers of a transformer and its output. Each translator learns to predict the final token distribution from a hidden state much earlier in the network, accounting for how representations get rotated, shifted, or stretched layer-to-layer. The result: you can eavesdrop on a model’s latent predictions at any depth, not just the end.
The interesting bit
This isn’t the logit lens, which naively unembeds raw hidden states. The tuned lens actually learns the distortion between layers, so its intermediate predictions are calibrated to match the full model’s output distribution. It’s interpretability with a training budget.
Key highlights
- Replaces the last m layers with a learned affine transform trained to minimize KL divergence from the true output
- Exposes what the model “knows” at layer n − m before computation finishes
- Ships with a Colab notebook and Hugging Face Space for poking around interactively
- Docker container provided for running training scripts reproducibly
- Python 3.9+, PyTorch 1.13.0+; installable via
pip install tuned-lens
Caveats
- Pre-1.0; the authors warn the public interface changes “regularly and without major version bumps”
- The paper is listed as “to appear” in the citation block, so peer-reviewed details aren’t yet available
Verdict
Worth a look if you’re doing mechanistic interpretability or debugging where transformers commit to predictions. Skip it if you need stable APIs for production work — this is research tooling with sharp edges.
Frequently asked
- What is AlignmentResearch/tuned-lens?
- A tuned lens lets you skip ahead in a transformer and see what it's thinking before it's done thinking.
- Is tuned-lens open source?
- Yes — AlignmentResearch/tuned-lens is open source, released under the MIT license.
- What language is tuned-lens written in?
- AlignmentResearch/tuned-lens is primarily written in Python.
- How popular is tuned-lens?
- AlignmentResearch/tuned-lens has 605 stars on GitHub.
- Where can I find tuned-lens?
- AlignmentResearch/tuned-lens is on GitHub at https://github.com/AlignmentResearch/tuned-lens.