AILab-CVC/YOLO-World
YOLO learns to read: open-vocab detection without retraining
A real-time object detector that recognizes categories it was never explicitly trained on, via text prompts.
Not currently ranked — collecting fresh signals.
star history
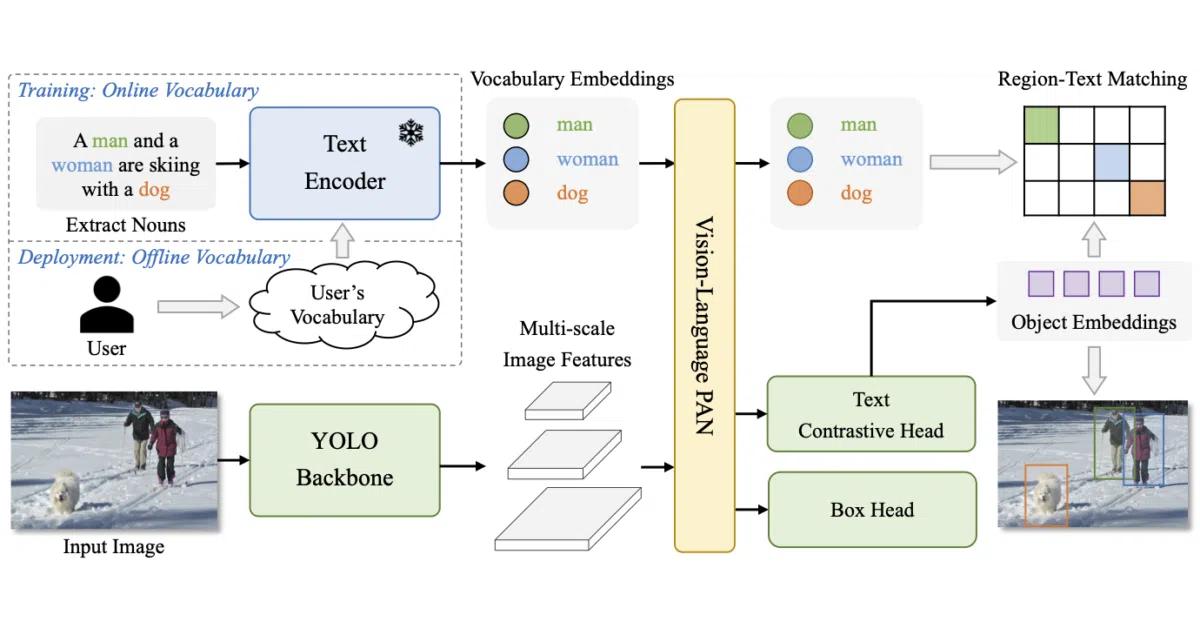
What it does YOLO-World is a YOLO-family detector that handles “open-vocabulary” detection: you describe objects with text (“person wearing a red hat,” “rusty bolt”) and it finds them, no custom training required. It also supports image prompts and segmentation. The project provides PyTorch weights, training code, and fine-tuning recipes for COCO or custom datasets.
The interesting bit The “prompt-then-detect” trick re-parameterizes vocabulary embeddings directly into the model weights, so after a one-time setup the detector runs at plain YOLO speed without dragging a text encoder through inference. It’s the rare case where the boring optimization is the headline feature.
Key highlights
- Pre-trained on detection, grounding, and image-text datasets; zero-shot evaluation tables provided for LVIS and COCO
- V2.1 release (Feb 2025) adds image-prompt training code and new weights
- Exports to ONNX and TFLite with INT8 quantization; ComfyUI and FiftyOne integrations available
- Supports high-resolution inference up to 1280×1280 for smaller objects
- Segmentation variant (YOLO-World-Seg) and EfficientSAM demo on HuggingFace Spaces
Caveats
- Still under active development; README warns of ongoing bugfixes and shifting APIs
- Some features (YOLO-World-Image, few-shot inference docs) are marked preview/coming soon
- Fine-tuning without
mask-refinewas only “preliminarily” fixed as of March 2024; check current status before relying on it
Verdict Worth a look if you need fast, deployable detection with flexible vocabularies and can’t afford per-task retraining. If you need guaranteed stability or mature tooling, wait for the dust to settle—or pin a known-good release.
Frequently asked
- What is AILab-CVC/YOLO-World?
- A real-time object detector that recognizes categories it was never explicitly trained on, via text prompts.
- Is YOLO-World open source?
- Yes — AILab-CVC/YOLO-World is open source, released under the GPL-3.0 license.
- What language is YOLO-World written in?
- AILab-CVC/YOLO-World is primarily written in Python.
- How popular is YOLO-World?
- AILab-CVC/YOLO-World has 6.4k stars on GitHub.
- Where can I find YOLO-World?
- AILab-CVC/YOLO-World is on GitHub at https://github.com/AILab-CVC/YOLO-World.