01
yooper/php-text-analysis
+0.1 ★/day→steady
A PHP-native library that brings text analysis, sentiment scoring, and document classification to codebases that can't justify a Python microservice.
A PHP-native library that brings text analysis, sentiment scoring, and document classification to codebases that can't justify a Python microservice.
Trains models that guess how words sound, because you can't ship a pronunciation dictionary for every proper noun the user will invent.
The original DBpedia Spotlight entity linker still works, but the maintainers have packed up and left for a cleaner, Apache-licensed rewrite.
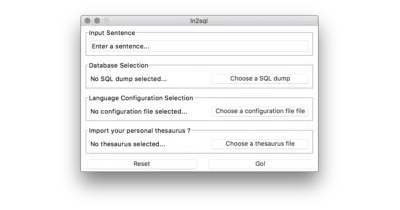
A Python tool that parses natural language questions and turns them into executable SQL using only a database dump—no live connection required.
A 2013-vintage open-science platform for sharing ML experiments, datasets, and results—now being retired in favor of a FastAPI rewrite.
A browser-native NLP annotation component for when you need to label text without leaving the DOM.
A Python library that treats Hindi, Tamil, Bengali, and friends as a family rather than isolated problems.
A community-built automation framework trying to make ML benchmarking reproducible across the chaos of GPUs, containers, and constantly shifting software stacks.
Matminer collects scattered materials-science datasets and featurizers into one library so researchers can stop writing the same data-prep scripts.
MeTA bundles tokenization, search indexes, topic models, and CRFs into one compiled toolkit for researchers who'd rather fight algorithms than package managers.
A scraped, cleaned corpus of WeChat public account articles in JSON format, released for research use.
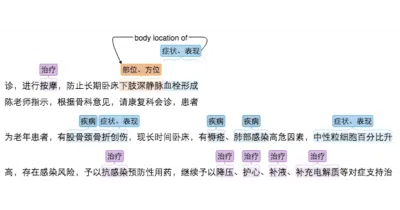
A Python library that reverse-engineers the 5W1H structure from news articles, because someone finally decided to treat reporters' training as a spec.
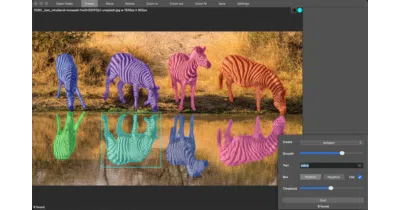
RectLabel is a commercial macOS app whose support repo reveals an unusually deep stack of offline ML models for labeling images and video.
A public repo of commented, tweakable scripts for Explosion's commercial annotation tool.
A scikit-learn-flavored toolkit that turns messy conversations into measurable social signals.
A self-contained Java morphological analyzer that ships its own dictionaries so you don't have to wrestle with MeCab.
Because finding the right robotics dataset shouldn't require a PhD in search-engine optimization.
A tidy, versioned dataset of 3,000 spoken digits for when your model needs to learn what "seven" sounds like at 8kHz.
Someone finally catalogued the chaos of German-language NLP resources so you don't have to hunt through CLARIN portals at 2am.
Someone finally collected all the scattered NLP relation-extraction datasets into one repo so you don't have to hunt through decade-old conference websites.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.