topoteretes/cognee · 28 Jun 2026 · Feature
Why Agent Memory Requires More Than Vector Search

Anthony Marino
Contributing Editor
Cognee is an open-source memory control plane that turns documents, interactions, and feedback into a self-improving knowledge graph so agents can recall facts, relationships, and context across sessions.
topoteretes/cognee
★24k stars Velocity · 7d +819 ★/day ↗accelerating
star history
The Statelessness Trap
Every call to a large language model begins with a blank slate. The model has no native memory of the previous turn, let alone the previous week. Developers paper over this by stuffing conversation history into the context window, but that approach scales linearly in cost and latency until it hits a hard limit. Retrieval-Augmented Generation was supposed to solve this by fetching relevant document chunks, yet the dominant vector-only approach embeds text into high-dimensional space and retrieves by cosine similarity. As critics have noted, this flattens document structure, strips away temporal information, and cannot distinguish between two people who share the same name. An agent asked about a job promotion cannot tell whether a fact is current or outdated, and it cannot trace how an introduction happened through a chain of intermediate relationships. For static document corpora, hybrid vector-and-keyword search is effective and hard to beat. For living, multi-session agent memory, it is amnesia by another name. The statelessness of LLM requests and the constraints of context windows are the foundational problem Cognee was built to solve.
Memory as a Control Plane
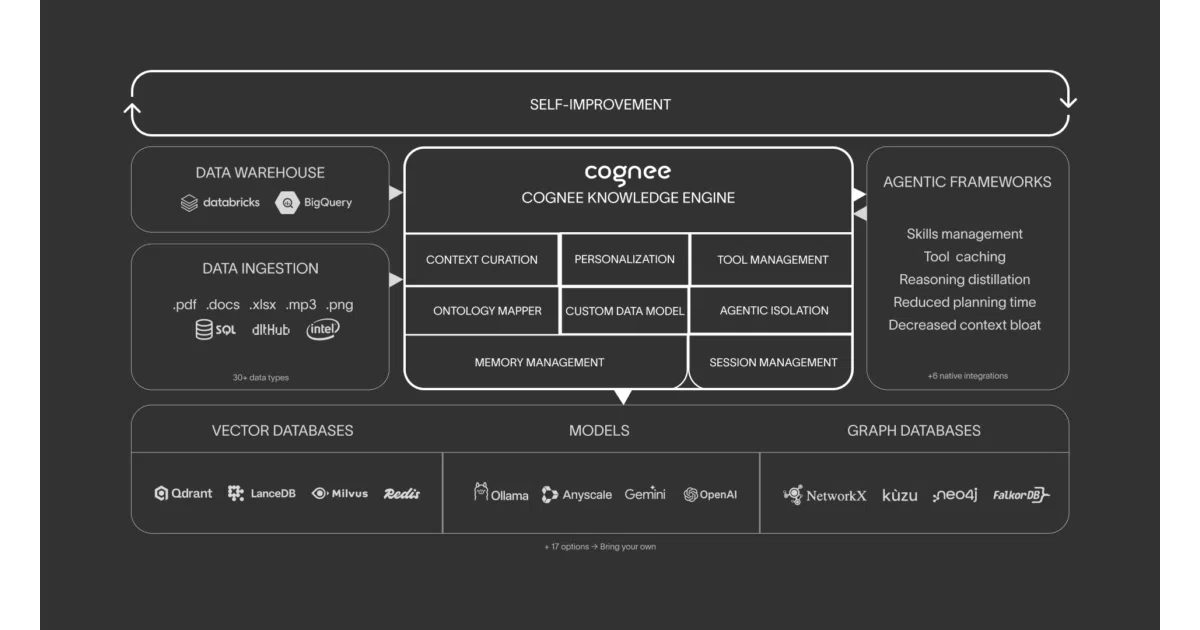
Cognee enters this gap with a deliberately architectural framing. Founded three years ago by Vasilije Markovic and backed by a $7.5 million seed round from investors including Pebblebed and angels from Google DeepMind, the project is incubated in the Berkeley Xcelerator. It has accumulated 17,500 GitHub stars and claims more than five million SDK runs per month, with over seventy organizations reportedly running production pipelines. Rather than marketing itself as another vector database, Cognee calls itself a memory control plane. The distinction is not cosmetic. A database stores and retrieves; a control plane orchestrates. Cognee’s surface API is built around four conceptual operations—remember, recall, improve, and forget—that treat memory as an active process rather than a passive repository. Under the hood, the pipeline decomposes these into add, cognify, memify, and search. The remember operation handles ingestion, recall routes queries, improve refines the graph based on feedback, and forget handles surgical deletion. This verb-centric design signals an intent to make memory feel like a native capability of an agent rather than a database query tacked onto a prompt.
The Unglamorous Pipeline
The value hides in the stages most users will never touch directly. Ingestion accepts more than thirty-eight formats, from PDFs and CSVs to audio and images, then deduplicates content and enforces permissions. The cognify stage classifies documents, extracts chunks, uses language models to identify entities and relationships, generates summaries, and commits edges into a graph while embedding every node. The memify stage then refines that graph: pruning stale nodes, strengthening connections based on usage, reweighting edges according to feedback, and adding derived facts. This is the self-improving loop that static RAG systems lack. The storage architecture is deliberately tripartite: Kuzu handles graph structure, LanceDB handles vector search, and SQLite handles relational metadata, with every graph node linked to an embedding so queries can auto-route between semantic similarity and graph traversal. The system exposes fourteen search modes, including temporal search, chain-of-thought traversal, and natural-language-to-Cypher translation. Separating short-term session memory from permanent long-term memory allows an agent to hold a fast conversational cache while still grounding every turn in a slowly evolving knowledge graph.
Enterprise Tailwinds
Cognee is not building in a vacuum. The broader RAG market is projected to grow from $1.92 billion to $10.20 billion by 2030, but enterprises are discovering that vector-only retrieval is poorly suited to governance and audit requirements. NetApp’s analysis argues that high-dimensional embeddings obscure provenance and lineage; they can return similarity scores but cannot explain relevance beyond mathematical proximity or provide the connective tissue for multi-hop reasoning. Graph RAG, by contrast, stores relationships explicitly, allowing every answer to be traced through concrete paths from question to nodes and source documents. Real-world deployments validate the shift: NASA’s People Analytics team uses a live knowledge graph to map employees, projects, and expertise for faster onboarding and internal mobility. Precina Health reported a one percent monthly HbA1c reduction using a graph-based patient copilot that reasons across cause-and-effect layers. Cedars-Sinai achieved 94.2 percent accuracy on an Alzheimer’s research task against a 49.9 percent baseline by traversing a biomedical graph exceeding 1.6 million edges.
Against this backdrop, Cognee has found production footholds. Bayer uses it for agentic research memory, having moved beyond a simple chatbot. The University of Wyoming launched a memory system in thirty days. Knowunity, serving forty thousand students, ran a proof-of-concept in two days after concluding that SQL and embedding approaches were insufficient. Dynamo deployed customer data enrichment in one month, and DeepMetis implemented on-prem memory without configuring a separate graph or vector database, reporting significantly increased retrieval accuracy. These adoptions suggest that for organizations with heterogeneous data and multi-step agent workflows, the overhead of graph construction pays off in cross-session continuity and factual grounding.
The Open-Source Wager
Cognee’s business model follows the modern infrastructure playbook. The full engine is open source and can run locally or on self-managed infrastructure indefinitely at no cost. Cognee Cloud adds managed workspaces, integrations with Slack, Notion, and Google Drive, and support tiers priced at a flat rate of $2.50 per million tokens processed plus monthly workspace fees. The project courts developers through agentic integrations—Claude Code, Codex, LangGraph, Cursor, and an MCP server—and recently ran a hackathon with $10,000 in prizes. The bet is that open-source adoption at the hobby and growth tiers will convert to cloud revenue as teams hit the complexity of production memory management.
Limits and Unfinished Business
The project is not without risks. For static documents, plain RAG remains a tough competitor. Frontier language models with enormous context windows—Gemini Pro, Claude Sonnet—have prompted debate over whether external retrieval is even necessary, though they trade latency, cost, and user control for convenience. Cognee’s three-storage backend, fourteen search modes, and six-stage pipeline are intricate in the way a Swiss watch is intricate: every gear must turn correctly, and a team with simple needs may find the machinery overwhelming. The cognitive-science framing is compelling, yet the academic literature on human-like memory systems admits that precise regulation of memory processes remains incompletely understood. Cognee’s automated pruning and reweighting are, in effect, educated guesses dressed in graph theory.
The unresolved tension is between structure and simplicity. If the future of AI is stateless API calls to ever-larger models, Cognee is sophisticated plumbing for a marginal problem. If the future is persistent, multi-agent systems that learn and reason across months of interaction, then a memory control plane that unifies vectors, graphs, and feedback loops becomes foundational. The enterprise adopters, the seed funding, and the trajectory of the GraphRAG literature all suggest the latter. Whether Cognee becomes the default substrate for agent memory or merely an influential blueprint depends on whether developers accept that remembering is harder than searching.
Sources
- I spent a year building agent memory on knowledge graphs ... - Reddit
- Top 10 Enterprise AI Use Cases with RAG and Knowledge Graphs
- Cognee - Open-Source Agent Memory Platform
- Building Agent Memory with Knowledge Graphs - The Neural Maze
- RAG for Enterprise: Use Cases, Platforms, and Production Best ...
- Pricing | Cognee - AI Memory Engine Plans
- Meet Lenny's Memory: Building context graphs for AI agents - Neo4j
- From "Trust Me" to "Prove It": Why Enterprises Need Graph RAG
- The Hangover Part AI: Where's My Context? | WeMakeDevs
- Leveraging Knowledge Graph-Based Human-Like Memory Systems ...
- 4 Real-World Success Stories Where GraphRAG Beats Standard RAG
- How Cognee Builds AI Memory for Agents