zai-org/ImageReward
CLIP measures similarity; ImageReward measures taste
To learn and evaluate human preferences for text-to-image generation so you can score, filter, and fine-tune diffusion models by actual human judgment.
Not currently ranked — collecting fresh signals.
star history
What it does
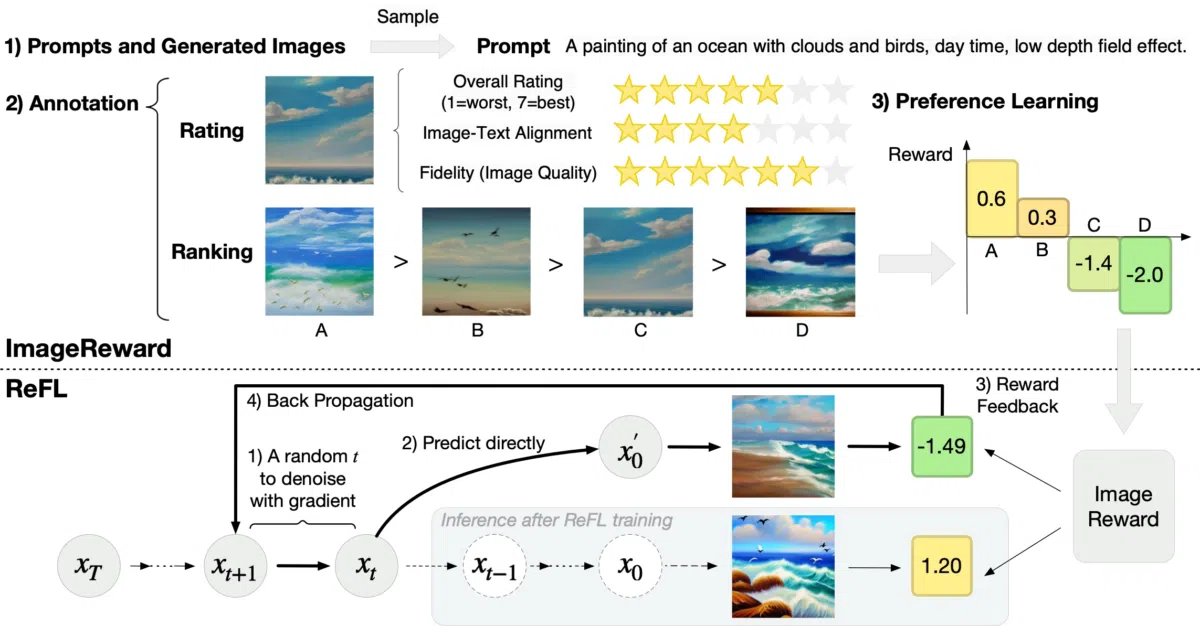
ImageReward is a reward model trained on 137k pairs of expert human comparisons to score text-to-image generations by human preference. It outperforms CLIP, Aesthetic, and BLIP on preference alignment, and includes ReFL (Reward Feedback Learning), a pipeline that uses those scores to directly optimize Stable Diffusion. The project ships as the image-reward PyPI package and includes a custom script for AUTOMATIC1111’s Stable Diffusion Web UI.
The interesting bit The Web UI integration does not just label images after the fact; it can auto-filter low-scoring generations before they appear in the gallery, and it embeds scores into PNG metadata for later review. Meanwhile, ReFL treats the reward model as a feedback signal to tune the diffusion model itself, with the authors reporting that ReFL-tuned Stable Diffusion wins 58.4% of human evaluations against the untuned base.
Key highlights
- Trained on 137k expert comparison pairs; beats CLIP by 38.6%, Aesthetic by 39.6%, and BLIP by 31.6% on preference understanding
- ReFL-tuned Stable Diffusion wins 58.4% of human side-by-sides against the base model
- Ships as the
image-rewardpackage with APIs for both scoring and fine-tuning - SD Web UI script supports lazy model loading, score-based filtering, and PNG info embedding
- Scores roughly follow a standard-normal distribution, so thresholding is straightforward
Caveats
- Benchmark reproduction is sensitive to the exact NVIDIA driver, CUDA, and PyTorch stack; the authors note last-decimal fluctuations around ±0.1 in other environments
- ReFL currently depends on pinned legacy versions of
diffusers,accelerate, anddatasets
Verdict Worth exploring if you need human-aligned quality scoring or want to experiment with RLHF-style diffusion fine-tuning. Less relevant if you are looking for a general visual encoder or have already moved on to the authors’ successor, VisionReward.
Frequently asked
- What is zai-org/ImageReward?
- To learn and evaluate human preferences for text-to-image generation so you can score, filter, and fine-tune diffusion models by actual human judgment.
- Is ImageReward open source?
- Yes — zai-org/ImageReward is open source, released under the Apache-2.0 license.
- What language is ImageReward written in?
- zai-org/ImageReward is primarily written in Python.
- How popular is ImageReward?
- zai-org/ImageReward has 1.7k stars on GitHub.
- Where can I find ImageReward?
- zai-org/ImageReward is on GitHub at https://github.com/zai-org/ImageReward.