wilson1yan/VideoGPT
Video generation by treating spacetime like a sentence
A minimal reference proving that VQ-VAE tokens and a GPT-style transformer can generate video competitive with GANs without the adversarial headache.
Not currently ranked — collecting fresh signals.
star history
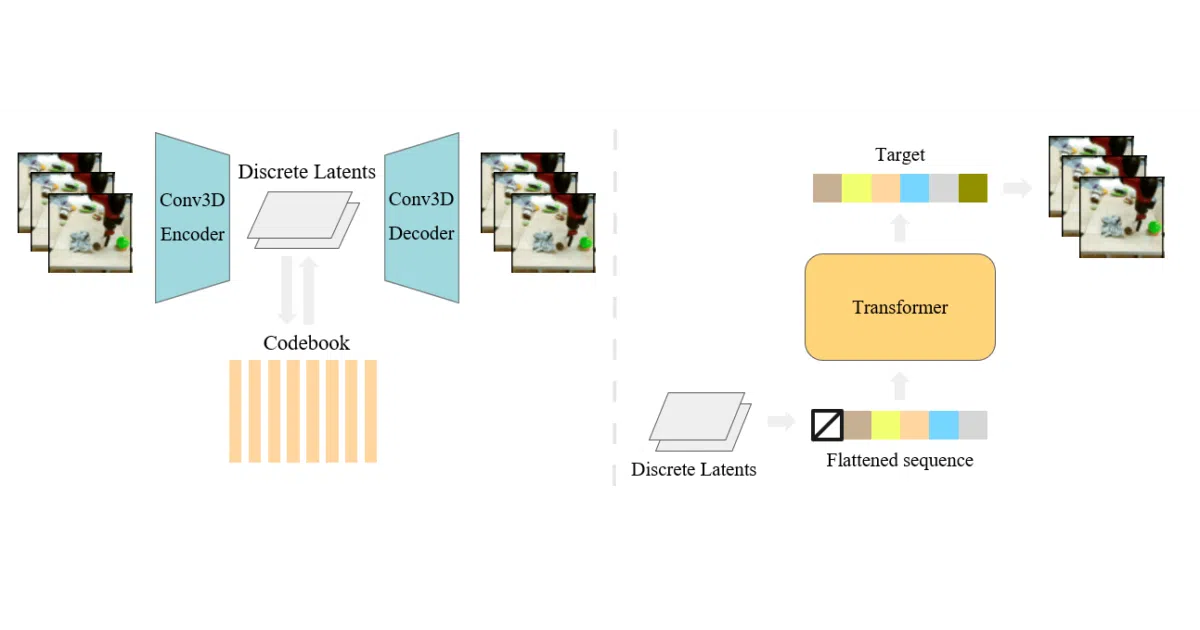
What it does VideoGPT compresses raw video into downsampled discrete tokens using a VQ-VAE built with 3D convolutions and axial self-attention. A plain GPT-like transformer then models those tokens autoregressively, using spatio-temporal position encodings to keep track of where each latent patch belongs in time and space.
The interesting bit The project treats video generation as a sequence-modeling problem rather than an adversarial game, betting that the simplicity of likelihood-based training outweighs the complexity of GAN dynamics. The authors explicitly keep the code clean enough to extend, even if that means leaving the messier, full-paper reproductions in another repository.
Key highlights
- VQ-VAE encoder compresses video into a discrete latent space via 3D convolutions and axial self-attention.
- GPT-style transformer predicts latent tokens autoregressively with spatio-temporal position encodings.
- Claims sample quality competitive with state-of-the-art GANs on the BAIR Robot dataset and high-fidelity results on UCF-101 and TGIF.
- Optional sparse attention through DeepSpeed for constrained compute budgets.
- Evaluation uses Frechet Video Distance and Inception Score, though the latter requires external code from the TGANv2 repository.
Caveats
- This repository prioritizes simplicity and extensibility over exact reproduction of the paper results; the full training setup is housed in a separate, less polished repo.
- Some evaluation metrics depend on external repositories rather than built-in scripts.
Verdict A solid starting point for researchers who want a readable, likelihood-based video generation baseline they can actually modify. Pure GAN devotees and anyone needing turnkey production pipelines should look elsewhere.
Frequently asked
- What is wilson1yan/VideoGPT?
- A minimal reference proving that VQ-VAE tokens and a GPT-style transformer can generate video competitive with GANs without the adversarial headache.
- Is VideoGPT open source?
- Yes — wilson1yan/VideoGPT is open source, released under the MIT license.
- What language is VideoGPT written in?
- wilson1yan/VideoGPT is primarily written in Jupyter Notebook.
- How popular is VideoGPT?
- wilson1yan/VideoGPT has 1.1k stars on GitHub.
- Where can I find VideoGPT?
- wilson1yan/VideoGPT is on GitHub at https://github.com/wilson1yan/VideoGPT.