vncorenlp/VnCoreNLP
Vietnamese NLP without the dependency hell
A self-contained Java pipeline that handles the messy reality of Vietnamese text: spaces don't mean what you think they mean.
Not currently ranked — collecting fresh signals.
star history
What it does
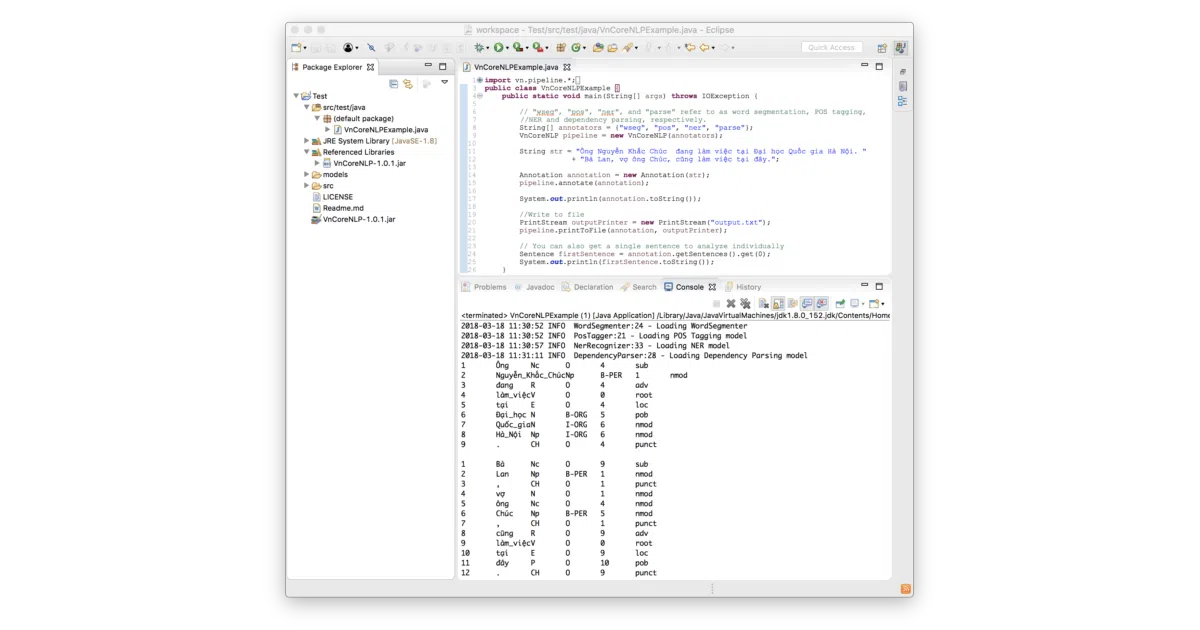
VnCoreNLP runs word segmentation, POS tagging, named entity recognition, and dependency parsing on Vietnamese text. It’s a single 27MB JAR plus 115MB of models—no external dependencies to wrestle with. You can call it from Java, the command line, or Python via a community wrapper.
The interesting bit
Vietnamese word segmentation is genuinely tricky: “Đại học Quốc gia Hà Nội” contains six space-separated tokens but only four semantic words. The toolkit handles this via an RDR-based segmenter (also available standalone as RDRsegmenter) and propagates those boundaries through the rest of the pipeline. The authors published the architecture at NAACL 2018 and have three papers backing individual components.
Key highlights
- Single JAR deployment; runs with
java -Xmx2g -jar - Pipeline is modular: pick any subset of
wseg,pos,ner,parse - Python wrapper (
py_vncorenlp) auto-downloads models from the repo - Output format is CoNLL-style: word index, form, POS, NER, head, dependency relation
- Components available à la carte: RDRsegmenter for segmentation only, VnMarMoT for POS tagging only
Caveats
- Java 1.8+ required; the Python wrapper is community-maintained, not official
- Last release appears to be 1.2; check if model freshness matters for your use case
- 2GB heap memory suggested; may not suit the most constrained environments
Verdict
Worth a look if you’re doing Vietnamese NLP and want something that works out of the box without PyTorch dependency chains. Skip it if you need a modern transformer-based architecture or if Java tooling is a hard no in your stack.
Frequently asked
- What is vncorenlp/VnCoreNLP?
- A self-contained Java pipeline that handles the messy reality of Vietnamese text: spaces don't mean what you think they mean.
- Is VnCoreNLP open source?
- Yes — vncorenlp/VnCoreNLP is an open-source project tracked on heatdrop.
- What language is VnCoreNLP written in?
- vncorenlp/VnCoreNLP is primarily written in Java.
- How popular is VnCoreNLP?
- vncorenlp/VnCoreNLP has 671 stars on GitHub.
- Where can I find VnCoreNLP?
- vncorenlp/VnCoreNLP is on GitHub at https://github.com/vncorenlp/VnCoreNLP.