understandable-machine-intelligence-lab/Quantus
A scoreboard for your saliency maps
Quantus gives neural-network explanations a report card instead of a shrug.
Not currently ranked — collecting fresh signals.
star history
What it does
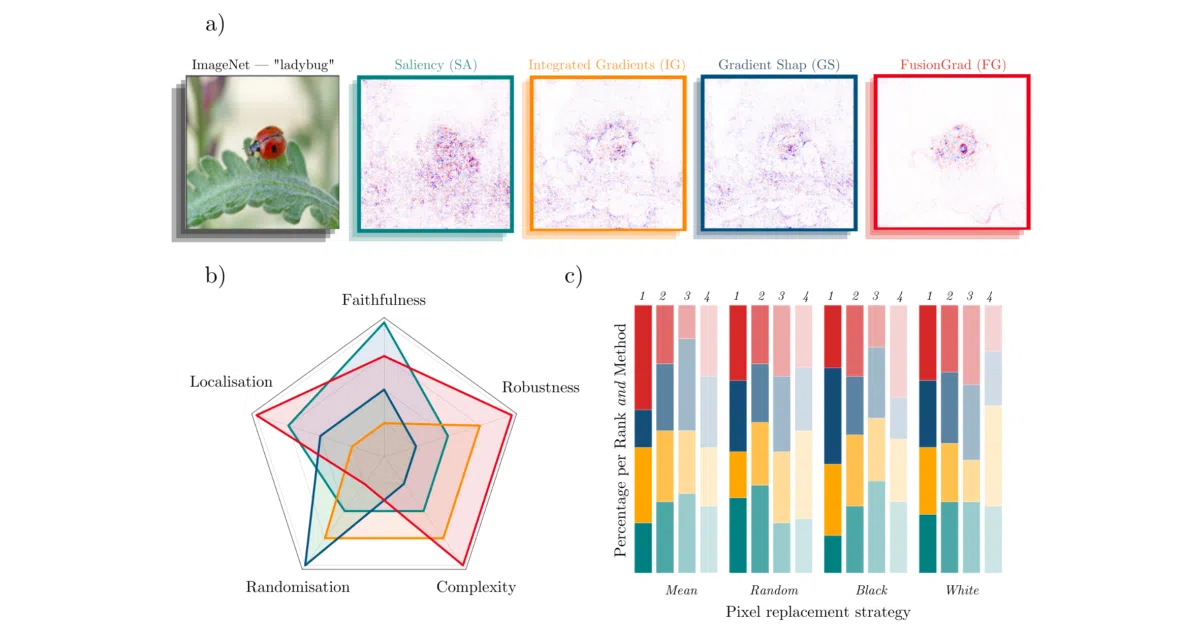
Quantus is a Python toolkit that grades XAI methods—saliency maps, integrated gradients, and the rest—using 35+ quantitative metrics. It works with both PyTorch and TensorFlow, and supports images, time-series, and tabular data. Think of it as a standardized test for whether your model’s “reasons” actually hold up.
The interesting bit
The library organizes metrics into six categories (faithfulness, robustness, localization, complexity, randomization, axiomatic) so you can compare explainers holistically rather than eyeballing heatmaps. It also plugs into popular explanation libraries like Captum and Zennit, so you don’t have to reimplement your attribution pipeline.
Key highlights
- 35+ metrics across 6 evaluation categories, with batch implementations for 12× speedup on faithfulness tests
- Supports multiple data modalities and both major deep-learning frameworks
- Published in JMLR (MLOSS track); actively maintained with new metrics like EfficientMPRT and SmoothMPRT
- Built-in integrations for Captum, tf-explain, and Zennit
- Colab and Binder tutorials ready to run
Caveats
- NLP support is listed as “next up”—not yet available
- The README warns the project is under active development, so version pinning matters for reproducibility
Verdict
Worth a look if you’re building or choosing XAI methods and tired of arguing about which heatmap “looks right.” Less useful if you just need a quick saliency map and don’t care about benchmarking it.
Frequently asked
- What is understandable-machine-intelligence-lab/Quantus?
- Quantus gives neural-network explanations a report card instead of a shrug.
- Is Quantus open source?
- Yes — understandable-machine-intelligence-lab/Quantus is an open-source project tracked on heatdrop.
- What language is Quantus written in?
- understandable-machine-intelligence-lab/Quantus is primarily written in Jupyter Notebook.
- How popular is Quantus?
- understandable-machine-intelligence-lab/Quantus has 671 stars on GitHub.
- Where can I find Quantus?
- understandable-machine-intelligence-lab/Quantus is on GitHub at https://github.com/understandable-machine-intelligence-lab/Quantus.