svc-develop-team/so-vits-svc
Make your favorite anime character sing, whether they want to or not
A deep-learning toolkit that converts singing voices while preserving pitch and intonation, no text intermediate required.
Not currently ranked — collecting fresh signals.
star history
What it does
so-vits-svc takes one singing voice and makes it sound like another—think cover songs performed by voices that don’t exist, or exist only in fiction. It extracts speech features using a SoftVC content encoder, pipes them straight into a VITS variant, and swaps the vocoder for NSF HiFiGAN to keep the audio from cutting out. The result: same melody, different singer.
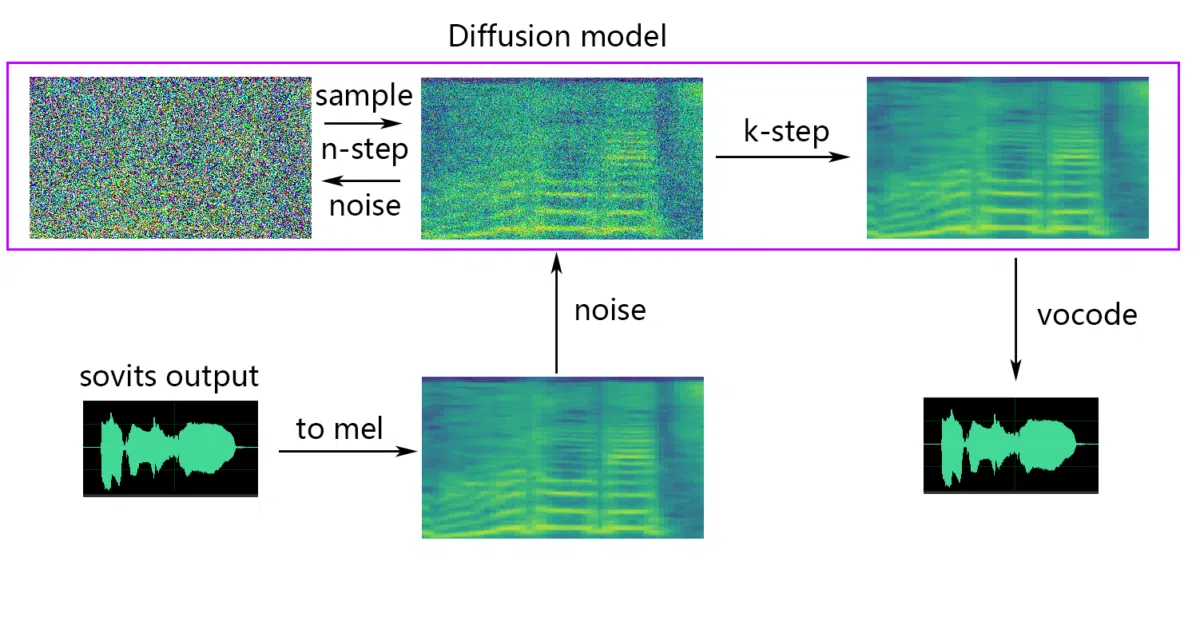
The interesting bit
The project skips the usual text-to-speech detour entirely. Instead of converting audio to phonemes and back, it works directly on acoustic features—preserving the original performance’s pitch bends and emotional wavers. The 4.1-Stable release adds shallow diffusion for quality polishing and borrows feature retrieval from RVC, a competing voice-conversion project.
Key highlights
- Supports seven different speech encoders, including ContentVec (recommended), Whisper-PPG, and WavLM
- Shallow diffusion model for post-hoc audio quality enhancement
- Static and dynamic sound fusion, plus loudness embedding for more natural dynamics
- Compatible with 4.0 model branches via
config.jsontweaks - Ships with a Colab notebook for cloud-based training
- AGPL 3.0 licensed, runs on Python 3.8.9
Caveats
- The repository is entering archive state; active development has wound down
- No models bundled—you train your own or source pretrained weights from third parties
- Terms of use are unusually restrictive: academic-only, no production deployment, mandatory attribution for platform uploads, and an explicit ban on political or religious use
- The developers’ stated intent is fictional characters only; they disclaim responsibility for real-person impersonation
Verdict
Worth a look if you’re doing research in singing voice conversion or want to prototype anime-style covers with full control over the pipeline. Skip it if you need a polished consumer app, real-time performance, or a project with ongoing maintenance; the forks and linked projects like MoeVoiceStudio and w-okada/voice-changer may serve you better.
Frequently asked
- What is svc-develop-team/so-vits-svc?
- A deep-learning toolkit that converts singing voices while preserving pitch and intonation, no text intermediate required.
- Is so-vits-svc open source?
- Yes — svc-develop-team/so-vits-svc is open source, released under the AGPL-3.0 license.
- What language is so-vits-svc written in?
- svc-develop-team/so-vits-svc is primarily written in Python.
- How popular is so-vits-svc?
- svc-develop-team/so-vits-svc has 28.1k stars on GitHub.
- Where can I find so-vits-svc?
- svc-develop-team/so-vits-svc is on GitHub at https://github.com/svc-develop-team/so-vits-svc.