soobinseo/Transformer-TTS
TTS on a Transformer budget: faster training, same griffin-lim caveats
A PyTorch reimplementation that swaps RNNs for self-attention in speech synthesis, trading training speed for the usual vocoder compromises.
Not currently ranked — collecting fresh signals.
star history
What it does
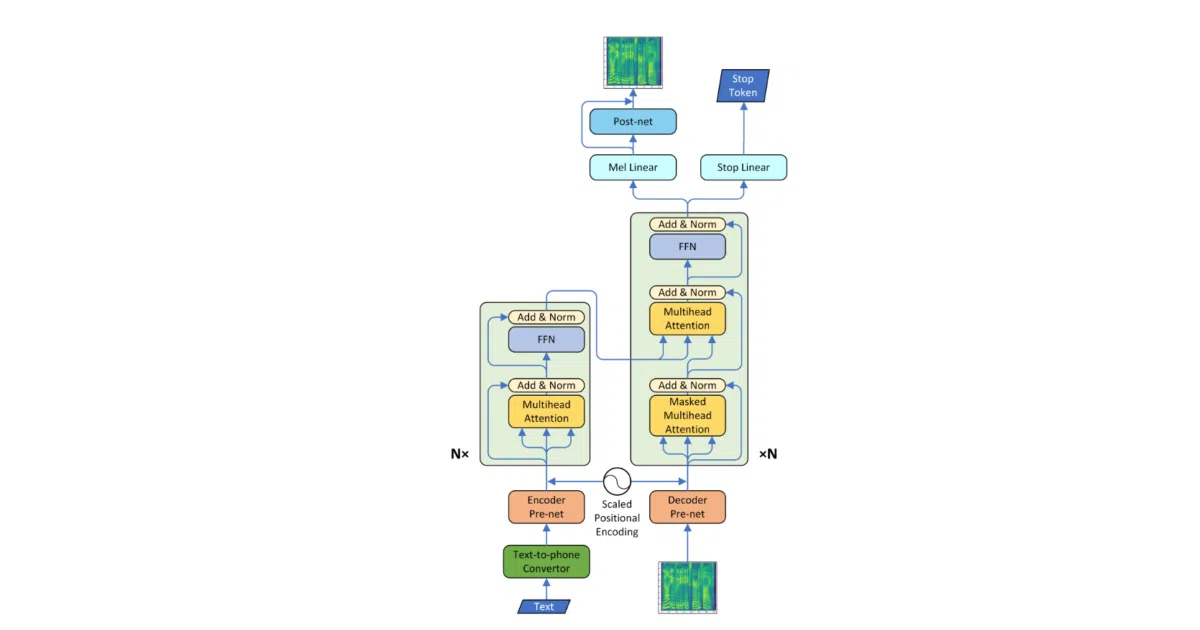
This is a PyTorch implementation of the 2018 paper “Neural Speech Synthesis with Transformer Network.” It replaces the recurrent seq2seq backbone of Tacotron-style TTS with a Transformer encoder-decoder, using multi-head attention to map text to mel spectrograms. A CBHG-based postnet (borrowed from Tacotron) refines the output, and Griffin-Lim reconstructs waveforms—no WaveNet vocoder involved.
The interesting bit
The author reports training roughly 3–4× faster than Tacotron, at about 0.5 seconds per step. The attention plots reveal something the paper doesn’t fully prepare you for: diagonal alignment only emerges in select multi-head attention layers after substantial training (around 15k steps), and decoder self-attention in particular stays messy. The scaled positional encoding also diverges from paper values—encoder alpha decays rather than rising to 4.
Key highlights
- Trains on LJSpeech (13,100 text-audio pairs) with a two-stage pipeline: autoregressive Transformer, then separate postnet training
- Pretrained models available (160k steps for AR model, 100k for postnet)
- Includes attention visualization for all 12 multi-head splits across 3 layers
- Noam-style warmup/decay learning rate scheduling
- Straightforward file layout:
hyperparams.pyfor configuration, separate scripts for data prep, training, and synthesis
Caveats
- Hard dependency on PyTorch 0.4.0, which is now ancient
- Generated samples at 160k steps are explicitly noted as “not converged yet”; long sentences suffer
- Stop token loss had to be abandoned—it broke training entirely
- Gradient clipping (norm=1) and learning rate tuning are described as critical and finicky
Verdict
Worth a look if you’re studying how Transformers behave in autoregressive audio generation, or need a faster-training baseline to iterate on. Skip it if you want production-ready TTS; the Griffin-Lim output, unconverged samples, and PyTorch 0.4.0 dependency make this a research reference rather than a shipping model.
Frequently asked
- What is soobinseo/Transformer-TTS?
- A PyTorch reimplementation that swaps RNNs for self-attention in speech synthesis, trading training speed for the usual vocoder compromises.
- Is Transformer-TTS open source?
- Yes — soobinseo/Transformer-TTS is open source, released under the MIT license.
- What language is Transformer-TTS written in?
- soobinseo/Transformer-TTS is primarily written in Python.
- How popular is Transformer-TTS?
- soobinseo/Transformer-TTS has 691 stars on GitHub.
- Where can I find Transformer-TTS?
- soobinseo/Transformer-TTS is on GitHub at https://github.com/soobinseo/Transformer-TTS.