sematic-ai/sematic
ML pipelines that graduate from laptop to K8s without rewriting
Sematic lets you write complex ML pipelines in pure Python, then run them locally or promote the same code to a Kubernetes cluster.
Not currently ranked — collecting fresh signals.
star history
What it does
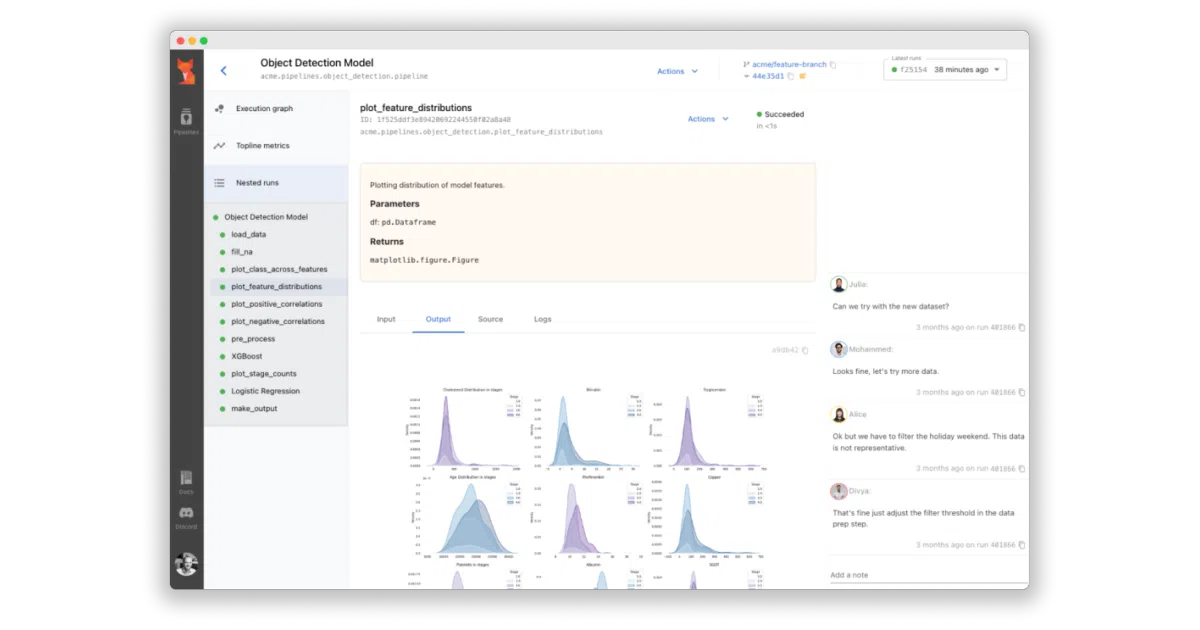
Sematic is an open-source Python framework for building end-to-end ML pipelines. You write plain Python functions, decorate them, and the tool handles orchestration, artifact tracking, and a web dashboard. It runs locally with a single pip install and sematic start, or deploys to Kubernetes via Helm for GPU and Spark workloads.
The interesting bit The self-driving-car pedigree shows in the emphasis on reproducibility: every input and output is persisted, pipelines can be rerun from any point in the graph, and steps cache automatically. The “local-to-cloud parity” claim means you don’t maintain two versions of the same pipeline code.
Key highlights
- Pure Python SDK with runtime type checking and dynamic graphs (conditionals, loops)
- Nested pipelines: compose smaller pipelines into larger ones arbitrarily
- Heterogeneous compute per step: mix CPU, GPU, Spark, and Ray in one pipeline
- Web dashboard for lineage, artifact visualization, and embedded Grafana panels
- Integrations: Snowflake, Pandas, Plotly, Matplotlib, Bazel, Git metadata tracking
Caveats
- The README emphasizes “arbitrarily complex” pipelines but doesn’t quantify scale limits or overhead
- Kubernetes deployment details are deferred to external docs; the Helm chart exists but isn’t described in depth here
Verdict Worth a look if you’re currently duct-taping Airflow, Jupyter notebooks, and ad-hoc shell scripts together. Probably overkill if your ML workflow is a single training script that finishes in ten minutes.
Frequently asked
- What is sematic-ai/sematic?
- Sematic lets you write complex ML pipelines in pure Python, then run them locally or promote the same code to a Kubernetes cluster.
- Is sematic open source?
- Yes — sematic-ai/sematic is open source, released under the Apache-2.0 license.
- What language is sematic written in?
- sematic-ai/sematic is primarily written in Python.
- How popular is sematic?
- sematic-ai/sematic has 999 stars on GitHub.
- Where can I find sematic?
- sematic-ai/sematic is on GitHub at https://github.com/sematic-ai/sematic.