santi-pdp/segan
When GANs learned to shush background noise
A 2017 TensorFlow implementation that applies adversarial training directly to raw audio waveforms for speech denoising.
Not currently ranked — collecting fresh signals.
star history
What it does
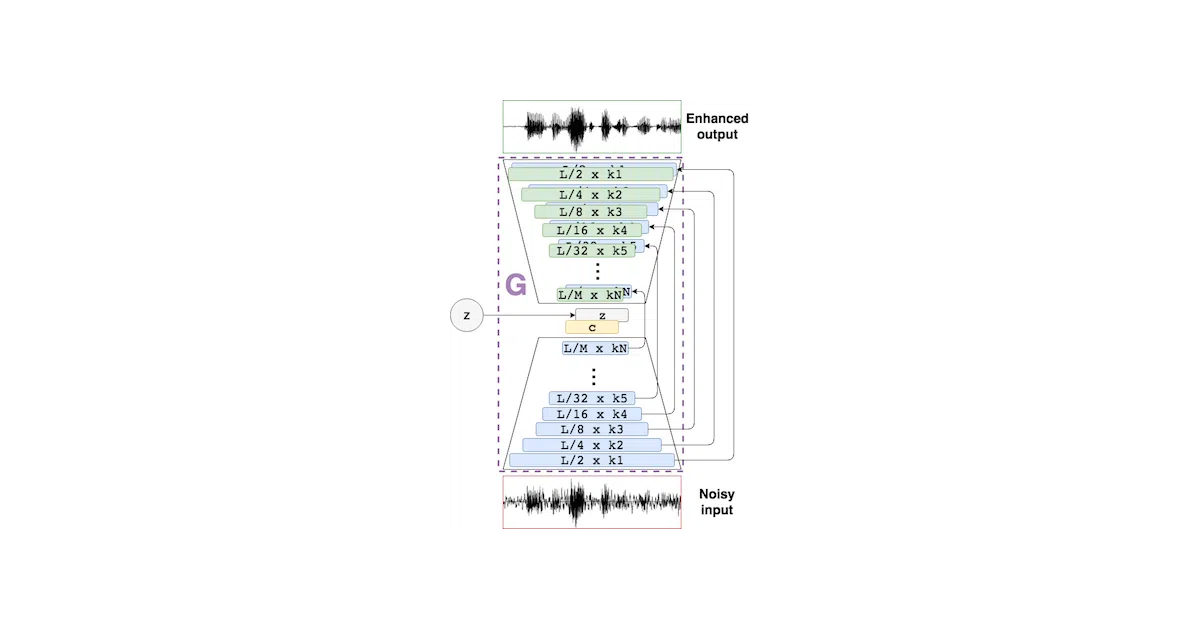
SEGAN removes noise from corrupted speech by training a fully convolutional generator against a discriminator, end-to-end on raw waveforms. It handles multiple noise types and speakers without needing to know who’s speaking. The project includes data prep scripts, training orchestration, and a pre-trained v1.1 model you can download.
The interesting bit
Instead of spectrograms or hand-engineered features, it works straight on the 1-D waveform—meaning the network has to learn its own representation of what “clean” sounds like. The adversarial loss is balanced against an L1 term weighted by 100, which the authors found keeps training from collapsing into pure mimicry.
Key highlights
- Trained on 40 noise conditions at various SNRs; tested on 20 unseen ones
- Multi-speaker, speaker-agnostic: no identity labels needed
- Includes
prepare_data.shto fetch and format the Edinburgh dataset automatically - GPU-multi training by default; CPU fallback if none available
- Pre-trained weights and test audio samples available from the authors’ site
Caveats
- Locked to Python 2.7 and TensorFlow 0.12—archaeology-grade dependencies at this point
- Authors explicitly state: “no support or assistance” and “no responsibility” for the code
- Inference requires careful flag-matching to the trained config; the
clean_wav.shwrapper helps but the CLI is still finicky
Verdict
Worth studying if you’re building modern audio GANs and want to see how the waveform-first approach was pioneered. Skip it if you need something production-ready today; the dependency stack alone is a time machine you may not want to enter.
Frequently asked
- What is santi-pdp/segan?
- A 2017 TensorFlow implementation that applies adversarial training directly to raw audio waveforms for speech denoising.
- Is segan open source?
- Yes — santi-pdp/segan is open source, released under the MIT license.
- What language is segan written in?
- santi-pdp/segan is primarily written in Python.
- How popular is segan?
- santi-pdp/segan has 861 stars on GitHub.
- Where can I find segan?
- santi-pdp/segan is on GitHub at https://github.com/santi-pdp/segan.