mitre/advmlthreatmatrix
MITRE maps how to break AI, ATT&CK-style
A framework that translates adversarial ML attacks into the familiar language of security operations.
★1.1k stars Other AI
Not currently ranked — collecting fresh signals.
star history
What it does
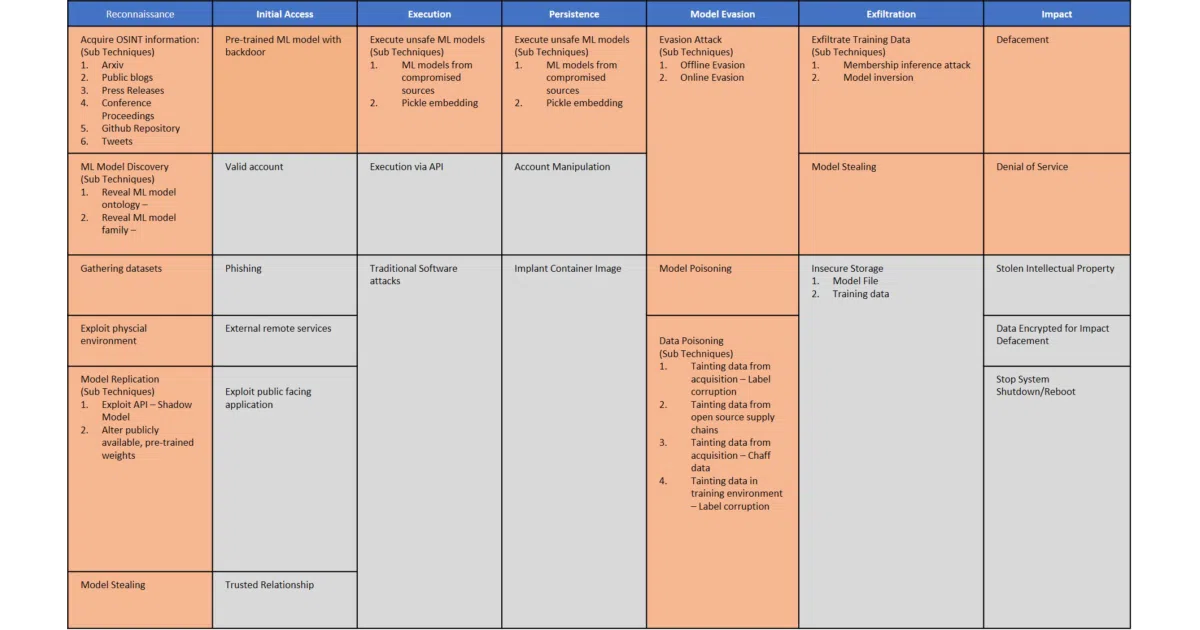
ATLAS (formerly the Adversarial ML Threat Matrix) catalogs real-world attacks on production machine learning systems—poisoning, evasion, model theft—using the same matrix format security teams already know from MITRE ATT&CK. The repo bundles a 101 guide, the matrix itself, and over a dozen case studies from Microsoft, Tesla, Google Translate, and others.
The interesting bit
The framework treats ML vulnerabilities as inherent to algorithms rather than implementation bugs, which means traditional patching won’t save you. The case studies are vetted against actual commercial systems, not lab demos—rare in a field that loves synthetic benchmarks.
Key highlights
- 13 curated case studies including Tay poisoning, ClearviewAI misconfiguration, and physical adversarial attacks on face recognition
- Contributions from Microsoft, MITRE, NVIDIA, Bosch, IBM, and academic groups
- “Adversarial ML 101” primer aimed at security analysts, not ML researchers
- Seeded with behaviors Microsoft and MITRE confirmed work against production systems
- Now lives at https://atlas.mitre.org with interactive navigator
Caveats
- The repo itself is largely documentation and links; active development has moved to the standalone ATLAS website
- Self-described as a “first-cut attempt” with acknowledged gaps
- Workshop timing references (Jan/Feb 2021) appear stale
Verdict
Security teams running ML in production should bookmark this. Pure ML researchers seeking novel attack techniques will find the case studies useful but the framework itself is operational, not technical.
Frequently asked
- What is mitre/advmlthreatmatrix?
- A framework that translates adversarial ML attacks into the familiar language of security operations.
- Is advmlthreatmatrix open source?
- Yes — mitre/advmlthreatmatrix is an open-source project tracked on heatdrop.
- How popular is advmlthreatmatrix?
- mitre/advmlthreatmatrix has 1.1k stars on GitHub.
- Where can I find advmlthreatmatrix?
- mitre/advmlthreatmatrix is on GitHub at https://github.com/mitre/advmlthreatmatrix.