marl/crepe
A neural network that listens for pitch, literally
CREPE runs a CNN directly on raw audio waveforms to estimate fundamental frequency, no spectrogram required.
Not currently ranked — collecting fresh signals.
star history
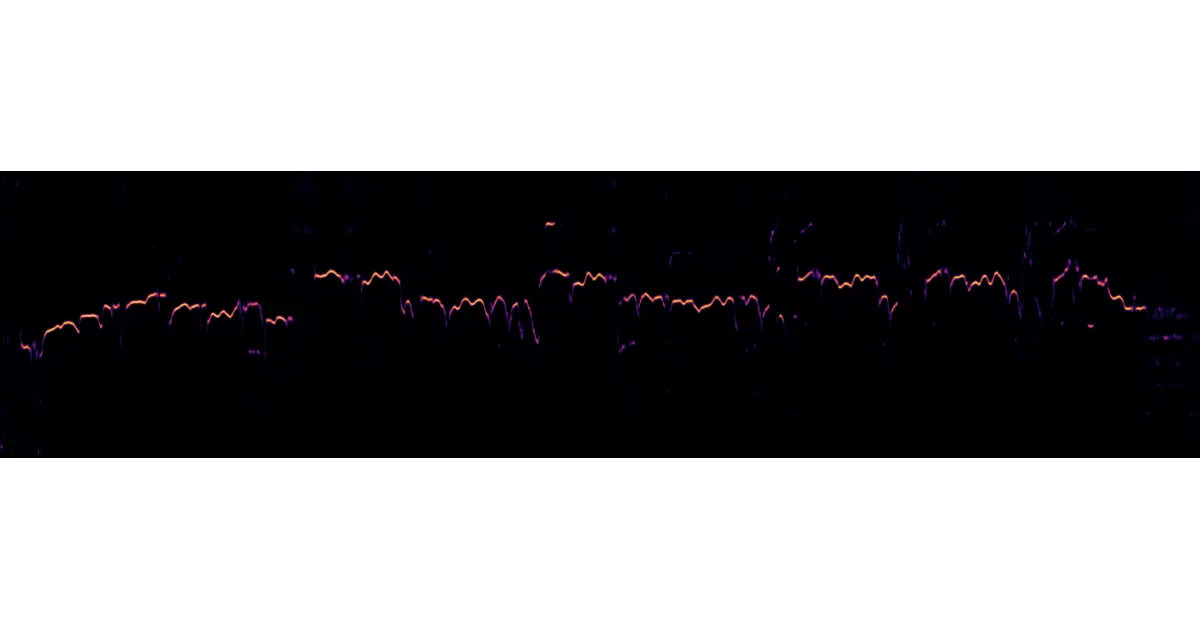
What it does CREPE is a monophonic pitch tracker: feed it a WAV file, get back timestamps, predicted fundamental frequency in Hz, and a confidence score for whether any pitch is present at all. It ships as a command-line tool and a Python module with a pre-trained model ready to go.
The interesting bit Instead of the usual spectral analysis, CREPE runs a deep convolutional network directly on the time-domain waveform. The authors claim it outperformed pYIN and SWIPE back in 2018. A neat post-paper tweak uses argmax-local weighted averaging—only the neighborhood around the peak activation contributes to the final pitch, which reportedly sharpens accuracy further.
Key highlights
- Outputs CSV with 10 ms resolution by default; hop size is adjustable
- Five model sizes from
tinytofullfor trading speed vs. accuracy - Optional Viterbi temporal smoothing
- Can dump the full 360-bin activation matrix or a salience plot
- Batch processing: point it at a folder of WAVs and walk away
Caveats
- WAV files only; anything else gets rejected at the door
- Trained on 16 kHz vocal and instrumental data, so your mileage may vary on other sources
- Keras with TensorFlow backend is strongly recommended; the model was trained on TF 1.6.0 and Keras 2.1.5
- GPU is “significantly faster”—the authors’ words, not a benchmark
Verdict Handy if you need pitch contours from monophonic audio and don’t want to hand-roll a pipeline. Skip it if you’re doing polyphonic transcription or need modern, actively maintained dependencies.
Frequently asked
- What is marl/crepe?
- CREPE runs a CNN directly on raw audio waveforms to estimate fundamental frequency, no spectrogram required.
- Is crepe open source?
- Yes — marl/crepe is open source, released under the MIT license.
- What language is crepe written in?
- marl/crepe is primarily written in Python.
- How popular is crepe?
- marl/crepe has 1.4k stars on GitHub.
- Where can I find crepe?
- marl/crepe is on GitHub at https://github.com/marl/crepe.