lyndonzheng/Pluralistic-Inpainting
One hole, many plausible faces: inpainting that embraces ambiguity
A CVPR 2019 project that generates multiple diverse completions for a single masked image instead of betting on one 'correct' answer.
Not currently ranked — collecting fresh signals.
star history
What it does
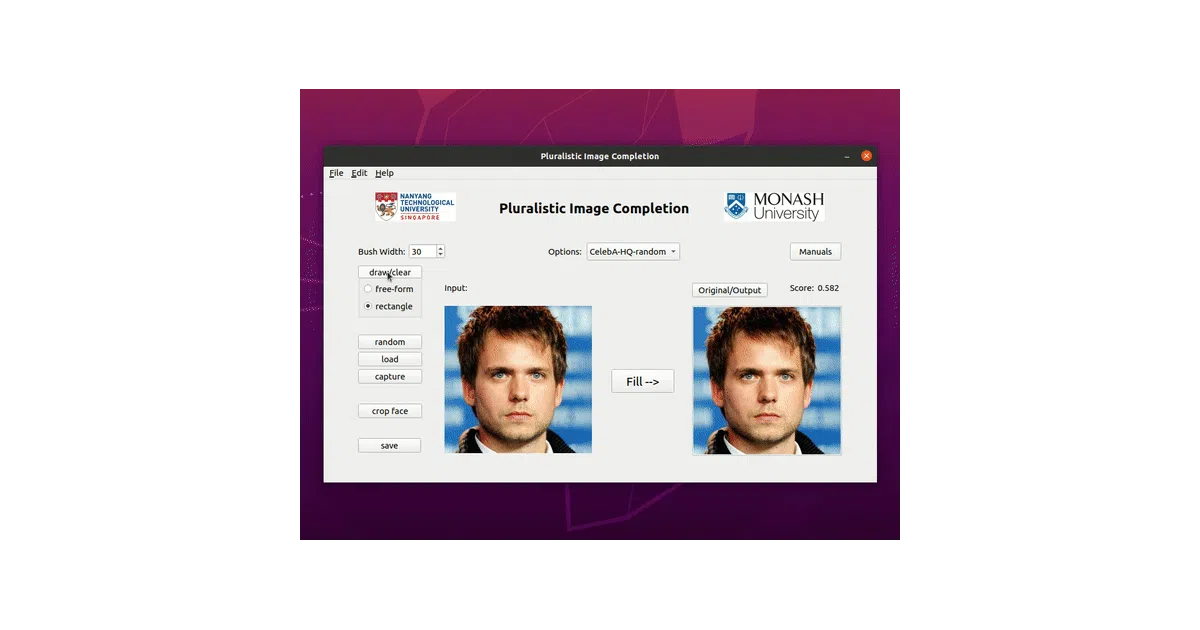
Given a photo with a masked region—say, a missing chunk of a face or a building facade—this model doesn’t guess one reconstruction. It generates multiple plausible completions with varying structure, color, and texture. The repo bundles training and testing scripts, pretrained models for CelebA, Paris, Places2, and ImageNet, plus a PyQt5 GUI for interactive editing.
The interesting bit
Most inpainting systems treat ambiguity as a bug; this one treats it as a feature. The “short+long term attention layer” copies context when available (mask half a face, get symmetric results) and invents freely when it’s not (mask the top of a face, get wild variety). The GUI even lets you scribble free-form masks and watch the hallucinations unfold in real time.
Key highlights
- Pretrained models for center masks (128×128 holes in 256×256 images) and random irregular masks
- Interactive GUI with face detection/auto-crop, camera capture, and brush-drawn masking
- Training tested on PyTorch 0.4.0; GUI verified up to PyTorch 1.7.0 / CUDA 11.2
- Visualizes training via Visdom; results saved to
results/or custom paths - Academic non-commercial license; commercial use requires contacting the authors
Caveats
- PyTorch 0.4.0 dependency for training feels archaeological; you’ll likely need to modernize or containerize
- The “Next” section lists “Higher resolution image completion” as unfinished, so don’t expect 4K out of the box
Verdict
Worth a spin if you’re researching generative diversity in computer vision or need a demoable inpainting toy with actual UI. Skip it if you need production-grade, high-res inpainting or a permissive commercial license.
Frequently asked
- What is lyndonzheng/Pluralistic-Inpainting?
- A CVPR 2019 project that generates multiple diverse completions for a single masked image instead of betting on one 'correct' answer.
- Is Pluralistic-Inpainting open source?
- Yes — lyndonzheng/Pluralistic-Inpainting is an open-source project tracked on heatdrop.
- What language is Pluralistic-Inpainting written in?
- lyndonzheng/Pluralistic-Inpainting is primarily written in Python.
- How popular is Pluralistic-Inpainting?
- lyndonzheng/Pluralistic-Inpainting has 690 stars on GitHub.
- Where can I find Pluralistic-Inpainting?
- lyndonzheng/Pluralistic-Inpainting is on GitHub at https://github.com/lyndonzheng/Pluralistic-Inpainting.